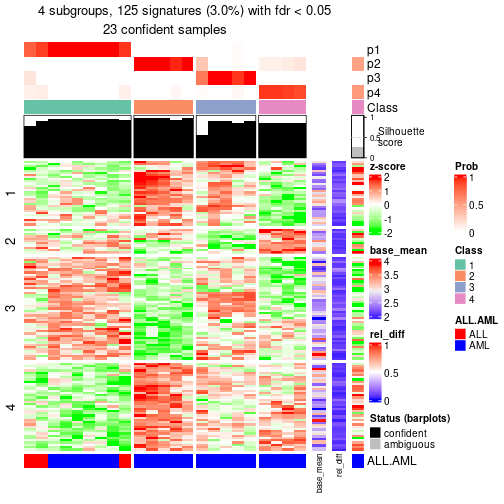
Date: 2021-07-22 16:02:47 CEST, cola version: 1.9.4
Document is loading...
First the variable is renamed to res_rh.
res_rh = rh
The partition hierarchy and all available functions which can be applied to res_rh object.
res_rh
#> A 'HierarchicalPartition' object with 'ATC:skmeans' method.
#> On a matrix with 4116 rows and 72 columns.
#> Performed in total 1350 partitions.
#> There are 6 groups under the following parameters:
#> - min_samples: 6
#> - mean_silhouette_cutoff: 0.9
#> - min_n_signatures: 102 (signatures are selected based on:)
#> - fdr_cutoff: 0.05
#> - group_diff (scaled values): 0.5
#>
#> Hierarchy of the partition:
#> 0, 72 cols
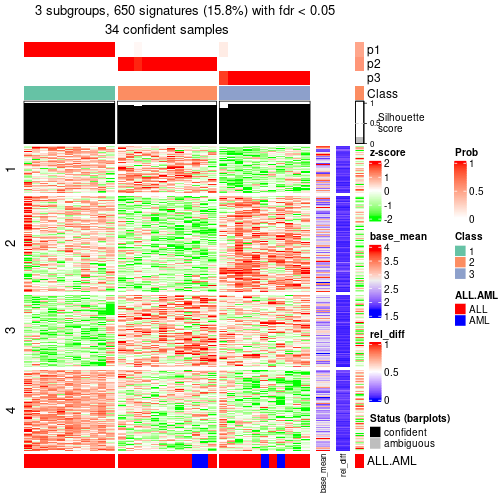
#> |-- 01, 35 cols, 650 signatures
#> | |-- 011, 11 cols (b)
#> | |-- 012, 13 cols, 4 signatures (c)
#> | `-- 013, 11 cols (b)
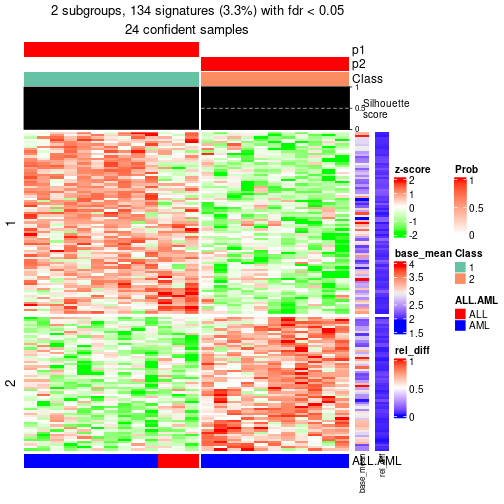
#> |-- 02, 24 cols, 134 signatures
#> | |-- 021, 13 cols, 35 signatures (c)
#> | `-- 022, 11 cols (b)
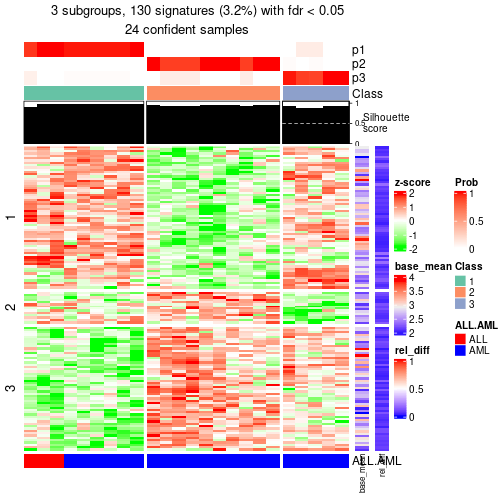
#> `-- 03, 13 cols, 6 signatures (c)
#> Stop reason:
#> b) Subgroup had too few columns.
#> c) There were too few signatures.
#>
#> Following methods can be applied to this 'HierarchicalPartition' object:
#> [1] "all_leaves" "all_nodes" "cola_report" "collect_classes"
#> [5] "colnames" "compare_signatures" "dimension_reduction" "functional_enrichment"
#> [9] "get_anno_col" "get_anno" "get_children_nodes" "get_classes"
#> [13] "get_matrix" "get_signatures" "is_leaf_node" "max_depth"
#> [17] "merge_node" "ncol" "node_info" "node_level"
#> [21] "nrow" "rownames" "show" "split_node"
#> [25] "suggest_best_k" "test_to_known_factors" "top_rows_heatmap" "top_rows_overlap"
#>
#> You can get result for a single node by e.g. object["01"]
The call of hierarchical_partition() was:
#> hierarchical_partition(data = m, anno = anno[, c("ALL.AML"), drop = FALSE], anno_col = c(ALL = "red",
#> AML = "blue"), cores = 4)
Dimension of the input matrix:
mat = get_matrix(res_rh)
dim(mat)
#> [1] 4116 72
All the methods that were tried:
res_rh@param$combination_method
#> [[1]]
#> [1] "ATC" "skmeans"
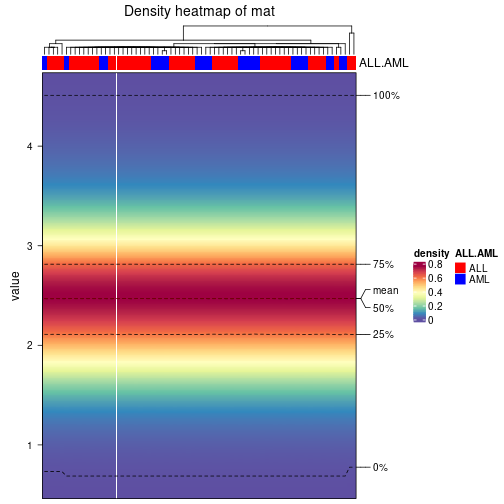
The density distribution for each sample is visualized as one column in the following heatmap. The clustering is based on the distance which is the Kolmogorov-Smirnov statistic between two distributions.
library(ComplexHeatmap)
densityHeatmap(mat, top_annotation = HeatmapAnnotation(df = get_anno(res_rh),
col = get_anno_col(res_rh)), ylab = "value", cluster_columns = TRUE, show_column_names = FALSE,
mc.cores = 1)
Some values about the hierarchy:
all_nodes(res_rh)
#> [1] "0" "01" "011" "012" "013" "02" "021" "022" "03"
all_leaves(res_rh)
#> [1] "011" "012" "013" "021" "022" "03"
node_info(res_rh)
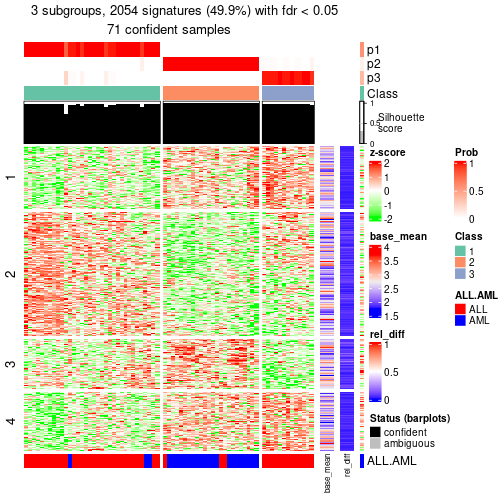
#> id best_method depth best_k n_columns n_signatures p_signatures is_leaf
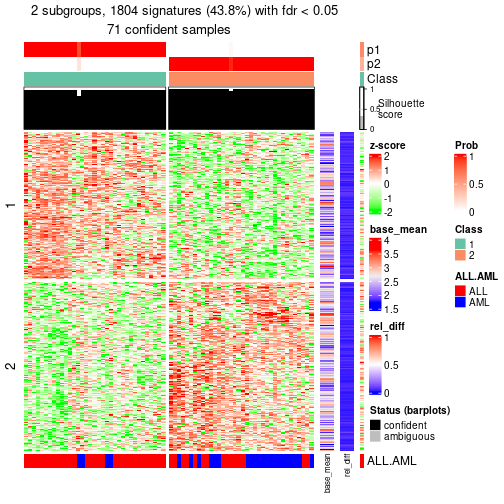
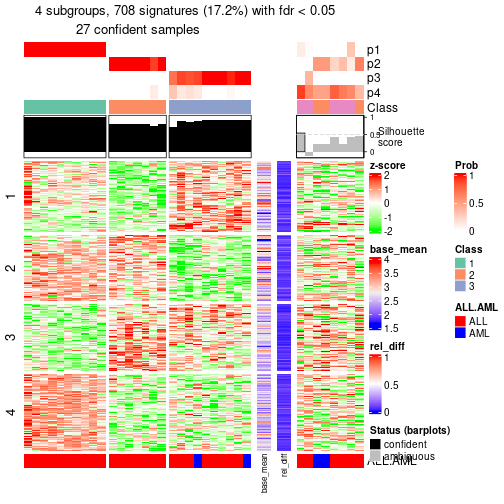
#> 1 0 ATC:skmeans 1 3 72 2054 0.499028 FALSE
#> 2 01 ATC:skmeans 2 3 35 650 0.157920 FALSE
#> 3 011 not applied 3 NA 11 NA NA TRUE
#> 4 012 ATC:skmeans 3 3 13 4 0.000972 TRUE
#> 5 013 not applied 3 NA 11 NA NA TRUE
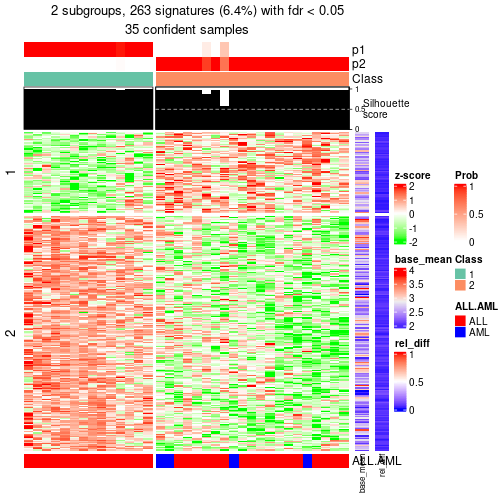
#> 6 02 ATC:skmeans 2 2 24 134 0.032556 FALSE
#> 7 021 ATC:skmeans 3 2 13 35 0.008503 TRUE
#> 8 022 not applied 3 NA 11 NA NA TRUE
#> 9 03 ATC:skmeans 2 2 13 6 0.001458 TRUE
In the output from node_info(), there are the following columns:
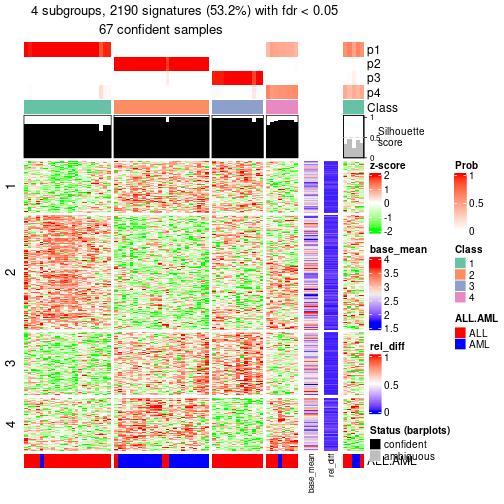
id: The node id.best_method: The best method selected.depth: Depth of the node in the hierarchy.best_k: Best number of groups of the partition on that node.n_columns: Number of columns in the submatrix.n_signatures: Number of signatures with the best_k.p_signatures: Proportion of hte signatures in total number of rows in the matrix.is_leaf: Whether the node is a leaf.Labels of nodes are encoded in a special way. The number of digits correspond to the depth of the node in the hierarchy and the value of the digits correspond to the index of the subgroup in the current node, E.g. a label of “012” means the node is the second subgroup of the partition which is the first subgroup of the root node.
Following table shows the best k (number of partitions) for each node in the
partition hierarchy. Clicking on the node name in the table goes to the
corresponding section for the partitioning on that node.
The cola vignette explains the definition of the metrics used for determining the best number of partitions.
suggest_best_k(res_rh)
| Node | Best method | Is leaf | Best k | 1-PAC | Mean silhouette | Concordance | #samples | |
|---|---|---|---|---|---|---|---|---|
| Node0 | ATC:skmeans | 3 | 1.00 | 0.97 | 0.98 | 72 | ** | |
| Node01 | ATC:skmeans | 3 | 1.00 | 0.95 | 0.98 | 35 | ** | |
| Node011-leaf | not applied | ✓ (b) | 11 | |||||
| Node012-leaf | ATC:skmeans | ✓ (c) | 3 | 1.00 | 0.99 | 1.00 | 13 | ** |
| Node013-leaf | not applied | ✓ (b) | 11 | |||||
| Node02 | ATC:skmeans | 2 | 1.00 | 1.00 | 1.00 | 24 | ** | |
| Node021-leaf | ATC:skmeans | ✓ (c) | 2 | 0.85 | 0.91 | 0.97 | 13 | |
| Node022-leaf | not applied | ✓ (b) | 11 | |||||
| Node03-leaf | ATC:skmeans | ✓ (c) | 2 | 0.71 | 0.91 | 0.96 | 13 |
Stop reason: b) Subgroup had too few columns. c) There were too few signatures.
**: 1-PAC > 0.95, *: 1-PAC > 0.9
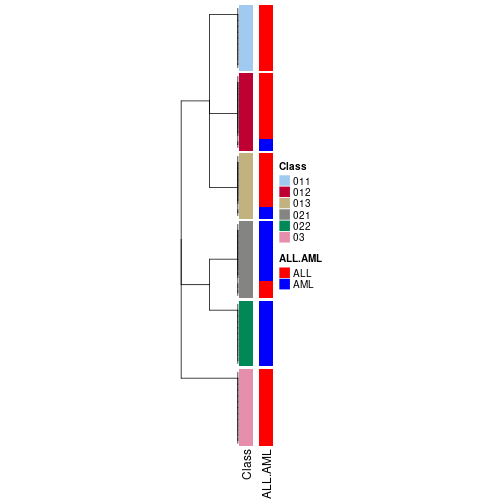
The nodes of the hierarchy can be merged by setting the merge_node parameters. Here we
control the hierarchy with the min_n_signatures parameter. The value of min_n_signatures is
from node_info().
collect_classes(res_rh, merge_node = merge_node_param(min_n_signatures = 134))
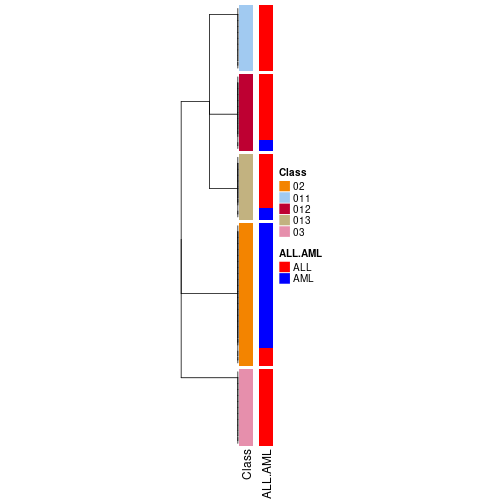
collect_classes(res_rh, merge_node = merge_node_param(min_n_signatures = 650))
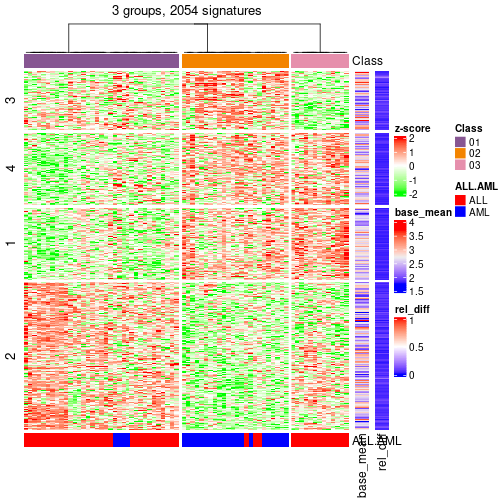
collect_classes(res_rh, merge_node = merge_node_param(min_n_signatures = 2054))
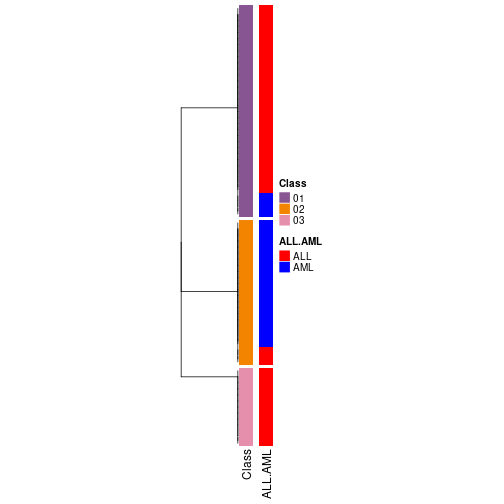
Following shows the table of the partitions (You need to click the show/hide code output link to see it).
get_classes(res_rh, merge_node = merge_node_param(min_n_signatures = 134))
#> sample_39 sample_40 sample_42 sample_47 sample_48 sample_49 sample_41 sample_43 sample_44 sample_45
#> "03" "03" "013" "012" "011" "03" "011" "012" "012" "012"
#> sample_46 sample_70 sample_71 sample_72 sample_68 sample_69 sample_67 sample_55 sample_56 sample_59
#> "012" "012" "013" "013" "011" "011" "013" "03" "03" "012"
#> sample_52 sample_53 sample_51 sample_50 sample_54 sample_57 sample_58 sample_60 sample_61 sample_65
#> "022" "021" "021" "021" "012" "022" "022" "012" "022" "022"
#> sample_66 sample_63 sample_64 sample_62 sample_1 sample_2 sample_3 sample_4 sample_5 sample_6
#> "013" "022" "022" "022" "03" "013" "03" "03" "011" "03"
#> sample_7 sample_8 sample_9 sample_10 sample_11 sample_12 sample_13 sample_14 sample_15 sample_16
#> "03" "03" "013" "013" "013" "021" "011" "013" "011" "012"
#> sample_17 sample_18 sample_19 sample_20 sample_21 sample_22 sample_23 sample_24 sample_25 sample_26
#> "011" "012" "012" "011" "011" "021" "03" "011" "021" "012"
#> sample_27 sample_34 sample_35 sample_36 sample_37 sample_38 sample_28 sample_29 sample_30 sample_31
#> "03" "022" "022" "021" "021" "021" "021" "013" "021" "022"
#> sample_32 sample_33
#> "021" "021"
get_classes(res_rh, merge_node = merge_node_param(min_n_signatures = 650))
#> sample_39 sample_40 sample_42 sample_47 sample_48 sample_49 sample_41 sample_43 sample_44 sample_45
#> "03" "03" "013" "012" "011" "03" "011" "012" "012" "012"
#> sample_46 sample_70 sample_71 sample_72 sample_68 sample_69 sample_67 sample_55 sample_56 sample_59
#> "012" "012" "013" "013" "011" "011" "013" "03" "03" "012"
#> sample_52 sample_53 sample_51 sample_50 sample_54 sample_57 sample_58 sample_60 sample_61 sample_65
#> "02" "02" "02" "02" "012" "02" "02" "012" "02" "02"
#> sample_66 sample_63 sample_64 sample_62 sample_1 sample_2 sample_3 sample_4 sample_5 sample_6
#> "013" "02" "02" "02" "03" "013" "03" "03" "011" "03"
#> sample_7 sample_8 sample_9 sample_10 sample_11 sample_12 sample_13 sample_14 sample_15 sample_16
#> "03" "03" "013" "013" "013" "02" "011" "013" "011" "012"
#> sample_17 sample_18 sample_19 sample_20 sample_21 sample_22 sample_23 sample_24 sample_25 sample_26
#> "011" "012" "012" "011" "011" "02" "03" "011" "02" "012"
#> sample_27 sample_34 sample_35 sample_36 sample_37 sample_38 sample_28 sample_29 sample_30 sample_31
#> "03" "02" "02" "02" "02" "02" "02" "013" "02" "02"
#> sample_32 sample_33
#> "02" "02"
get_classes(res_rh, merge_node = merge_node_param(min_n_signatures = 2054))
#> sample_39 sample_40 sample_42 sample_47 sample_48 sample_49 sample_41 sample_43 sample_44 sample_45
#> "03" "03" "01" "01" "01" "03" "01" "01" "01" "01"
#> sample_46 sample_70 sample_71 sample_72 sample_68 sample_69 sample_67 sample_55 sample_56 sample_59
#> "01" "01" "01" "01" "01" "01" "01" "03" "03" "01"
#> sample_52 sample_53 sample_51 sample_50 sample_54 sample_57 sample_58 sample_60 sample_61 sample_65
#> "02" "02" "02" "02" "01" "02" "02" "01" "02" "02"
#> sample_66 sample_63 sample_64 sample_62 sample_1 sample_2 sample_3 sample_4 sample_5 sample_6
#> "01" "02" "02" "02" "03" "01" "03" "03" "01" "03"
#> sample_7 sample_8 sample_9 sample_10 sample_11 sample_12 sample_13 sample_14 sample_15 sample_16
#> "03" "03" "01" "01" "01" "02" "01" "01" "01" "01"
#> sample_17 sample_18 sample_19 sample_20 sample_21 sample_22 sample_23 sample_24 sample_25 sample_26
#> "01" "01" "01" "01" "01" "02" "03" "01" "02" "01"
#> sample_27 sample_34 sample_35 sample_36 sample_37 sample_38 sample_28 sample_29 sample_30 sample_31
#> "03" "02" "02" "02" "02" "02" "02" "01" "02" "02"
#> sample_32 sample_33
#> "02" "02"
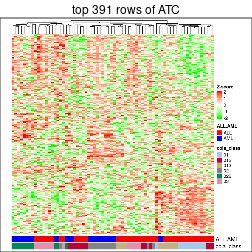
Heatmaps of the top rows:
top_rows_heatmap(res_rh)
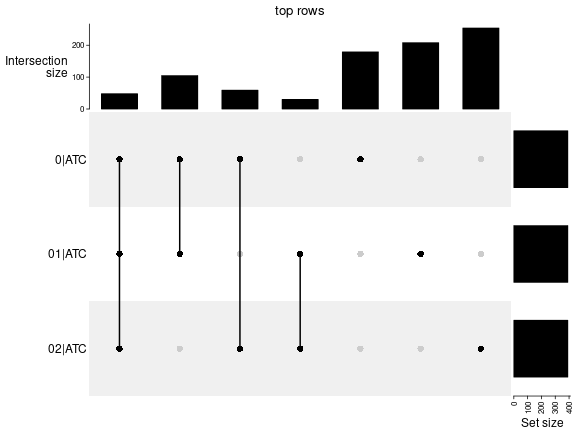
Top rows on each node:
top_rows_overlap(res_rh, method = "upset")
UMAP plot which shows how samples are separated.
par(mfrow = c(1, 2))
dimension_reduction(res_rh, merge_node = merge_node_param(min_n_signatures = 134),
method = "UMAP", top_value_method = "SD", top_n = 500, scale_rows = FALSE)
dimension_reduction(res_rh, merge_node = merge_node_param(min_n_signatures = 134),
method = "UMAP", top_value_method = "ATC", top_n = 500, scale_rows = TRUE)

par(mfrow = c(1, 2))
dimension_reduction(res_rh, merge_node = merge_node_param(min_n_signatures = 650),
method = "UMAP", top_value_method = "SD", top_n = 500, scale_rows = FALSE)
dimension_reduction(res_rh, merge_node = merge_node_param(min_n_signatures = 650),
method = "UMAP", top_value_method = "ATC", top_n = 500, scale_rows = TRUE)

par(mfrow = c(1, 2))
dimension_reduction(res_rh, merge_node = merge_node_param(min_n_signatures = 2054),
method = "UMAP", top_value_method = "SD", top_n = 500, scale_rows = FALSE)
dimension_reduction(res_rh, merge_node = merge_node_param(min_n_signatures = 2054),
method = "UMAP", top_value_method = "ATC", top_n = 500, scale_rows = TRUE)

Signatures on the heatmap are the union of all signatures found on every node on the hierarchy. The number of k-means on rows are automatically selected by the function.
get_signatures(res_rh, merge_node = merge_node_param(min_n_signatures = 134))
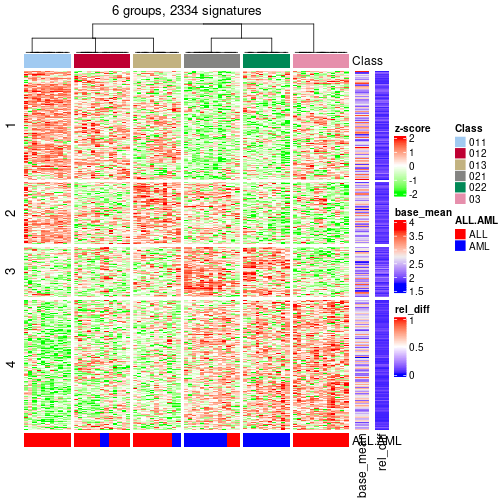
get_signatures(res_rh, merge_node = merge_node_param(min_n_signatures = 650))
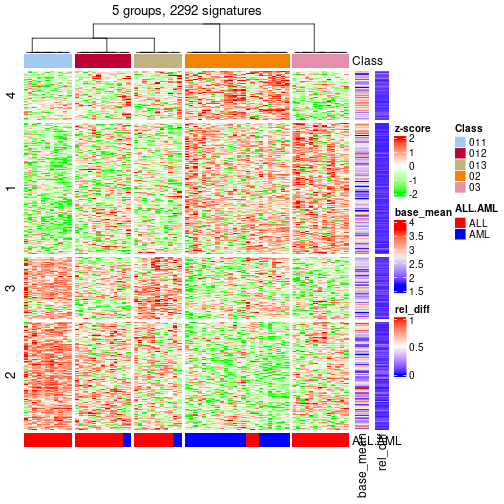
get_signatures(res_rh, merge_node = merge_node_param(min_n_signatures = 2054))
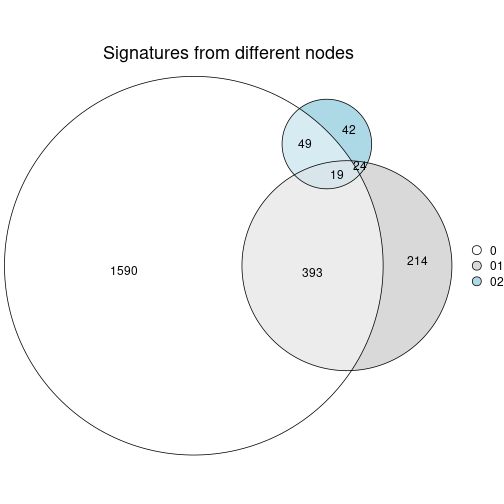
Compare signatures from different nodes:
compare_signatures(res_rh, verbose = FALSE)
If there are too many signatures, top_signatures = ... can be set to only show the
signatures with the highest FDRs. Note it only works on every node and the final signatures
are the union of all signatures of all nodes.
# code only for demonstration
# e.g. to show the top 500 most significant rows on each node.
tb = get_signature(res_rh, top_signatures = 500)
Test correlation between subgroups and known annotations. If the known annotation is numeric, one-way ANOVA test is applied, and if the known annotation is discrete, chi-squared contingency table test is applied.
test_to_known_factors(res_rh, merge_node = merge_node_param(min_n_signatures = 134))
#> ALL.AML
#> class 5.34e-09
test_to_known_factors(res_rh, merge_node = merge_node_param(min_n_signatures = 650))
#> ALL.AML
#> class 2.8e-09
test_to_known_factors(res_rh, merge_node = merge_node_param(min_n_signatures = 2054))
#> ALL.AML
#> class 1.88e-10
Child nodes: Node01 , Node02 , Node03-leaf .
The object with results only for a single top-value method and a single partitioning method can be extracted as:
res = res_rh["0"]
A summary of res and all the functions that can be applied to it:
res
#> A 'ConsensusPartition' object with k = 2, 3, 4.
#> On a matrix with 3910 rows and 72 columns.
#> Top rows (391) are extracted by 'ATC' method.
#> Subgroups are detected by 'skmeans' method.
#> Performed in total 150 partitions by row resampling.
#> Best k for subgroups seems to be 3.
#>
#> Following methods can be applied to this 'ConsensusPartition' object:
#> [1] "cola_report" "collect_classes" "collect_plots"
#> [4] "collect_stats" "colnames" "compare_partitions"
#> [7] "compare_signatures" "consensus_heatmap" "dimension_reduction"
#> [10] "functional_enrichment" "get_anno_col" "get_anno"
#> [13] "get_classes" "get_consensus" "get_matrix"
#> [16] "get_membership" "get_param" "get_signatures"
#> [19] "get_stats" "is_best_k" "is_stable_k"
#> [22] "membership_heatmap" "ncol" "nrow"
#> [25] "plot_ecdf" "predict_classes" "rownames"
#> [28] "select_partition_number" "show" "suggest_best_k"
#> [31] "test_to_known_factors" "top_rows_heatmap"
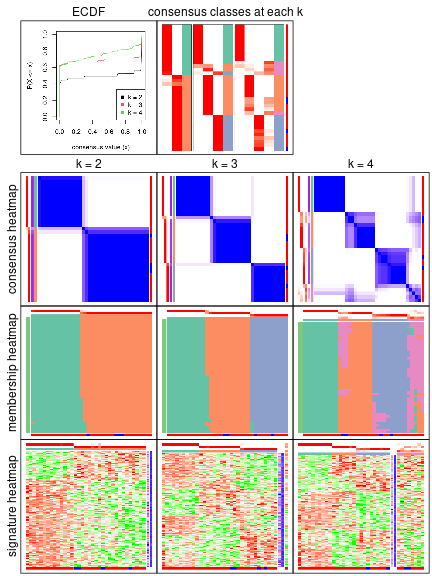
collect_plots() function collects all the plots made from res for all k (number of subgroups)
into one single page to provide an easy and fast comparison between different k.
collect_plots(res)
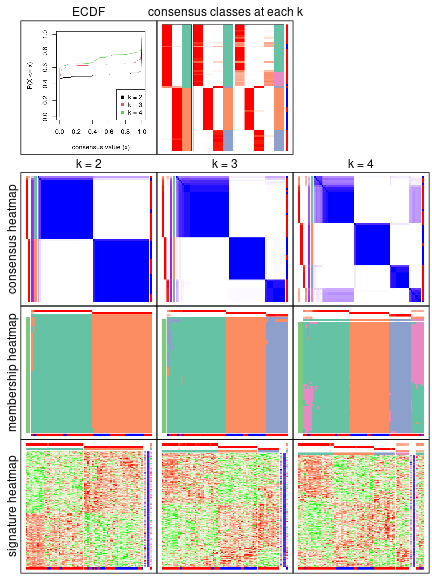
The plots are:
k and the heatmap of
predicted classes for each k.k.k.k.All the plots in panels can be made by individual functions and they are plotted later in this section.
select_partition_number() produces several plots showing different
statistics for choosing “optimized” k. There are following statistics:
k;k, the area increased is defined as \(A_k - A_{k-1}\).The detailed explanations of these statistics can be found in the cola vignette.
Generally speaking, higher 1-PAC score, higher mean silhouette score or higher
concordance corresponds to better partition. Rand index and Jaccard index
measure how similar the current partition is compared to partition with k-1.
If they are too similar, we won't accept k is better than k-1.
select_partition_number(res)
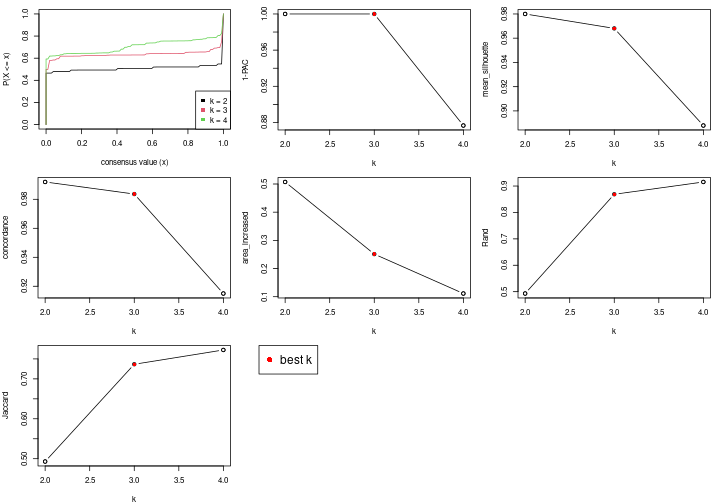
The numeric values for all these statistics can be obtained by get_stats().
get_stats(res)
#> k 1-PAC mean_silhouette concordance area_increased Rand Jaccard
#> 2 2 1.000 0.980 0.992 0.507 0.493 0.493
#> 3 3 1.000 0.968 0.984 0.251 0.869 0.737
#> 4 4 0.877 0.888 0.915 0.111 0.915 0.772
suggest_best_k() suggests the best \(k\) based on these statistics. The rules are as follows:
suggest_best_k(res)
#> [1] 3
#> attr(,"optional")
#> [1] 2
There is also optional best \(k\) = 2 that is worth to check.
Following is the table of the partitions (You need to click the show/hide
code output link to see it). The membership matrix (columns with name p*)
is inferred by
clue::cl_consensus()
function with the SE method. Basically the value in the membership matrix
represents the probability to belong to a certain group. The finall subgroup
label for an item is determined with the group with highest probability it
belongs to.
In get_classes() function, the entropy is calculated from the membership
matrix and the silhouette score is calculated from the consensus matrix.
cbind(get_classes(res, k = 2), get_membership(res, k = 2))
#> class entropy silhouette p1 p2
#> sample_39 2 0.000 0.999 0.00 1.00
#> sample_40 2 0.000 0.999 0.00 1.00
#> sample_42 1 0.000 0.984 1.00 0.00
#> sample_47 1 0.000 0.984 1.00 0.00
#> sample_48 1 0.000 0.984 1.00 0.00
#> sample_49 2 0.000 0.999 0.00 1.00
#> sample_41 1 0.000 0.984 1.00 0.00
#> sample_43 1 0.000 0.984 1.00 0.00
#> sample_44 1 0.000 0.984 1.00 0.00
#> sample_45 1 0.000 0.984 1.00 0.00
#> sample_46 1 0.000 0.984 1.00 0.00
#> sample_70 1 0.000 0.984 1.00 0.00
#> sample_71 1 0.000 0.984 1.00 0.00
#> sample_72 1 0.000 0.984 1.00 0.00
#> sample_68 1 0.000 0.984 1.00 0.00
#> sample_69 1 0.000 0.984 1.00 0.00
#> sample_67 1 0.000 0.984 1.00 0.00
#> sample_55 2 0.000 0.999 0.00 1.00
#> sample_56 2 0.000 0.999 0.00 1.00
#> sample_59 1 0.000 0.984 1.00 0.00
#> sample_52 2 0.000 0.999 0.00 1.00
#> sample_53 2 0.000 0.999 0.00 1.00
#> sample_51 2 0.000 0.999 0.00 1.00
#> sample_50 2 0.000 0.999 0.00 1.00
#> sample_54 1 0.000 0.984 1.00 0.00
#> sample_57 2 0.000 0.999 0.00 1.00
#> sample_58 2 0.000 0.999 0.00 1.00
#> sample_60 1 0.584 0.833 0.86 0.14
#> sample_61 2 0.000 0.999 0.00 1.00
#> sample_65 2 0.000 0.999 0.00 1.00
#> sample_66 1 0.000 0.984 1.00 0.00
#> sample_63 2 0.000 0.999 0.00 1.00
#> sample_64 2 0.000 0.999 0.00 1.00
#> sample_62 2 0.000 0.999 0.00 1.00
#> sample_1 2 0.242 0.957 0.04 0.96
#> sample_2 1 0.000 0.984 1.00 0.00
#> sample_3 2 0.000 0.999 0.00 1.00
#> sample_4 1 0.971 0.339 0.60 0.40
#> sample_5 1 0.000 0.984 1.00 0.00
#> sample_6 2 0.000 0.999 0.00 1.00
#> sample_7 2 0.000 0.999 0.00 1.00
#> sample_8 2 0.000 0.999 0.00 1.00
#> sample_9 1 0.000 0.984 1.00 0.00
#> sample_10 1 0.000 0.984 1.00 0.00
#> sample_11 1 0.000 0.984 1.00 0.00
#> sample_12 2 0.000 0.999 0.00 1.00
#> sample_13 1 0.000 0.984 1.00 0.00
#> sample_14 1 0.000 0.984 1.00 0.00
#> sample_15 1 0.000 0.984 1.00 0.00
#> sample_16 1 0.000 0.984 1.00 0.00
#> sample_17 1 0.000 0.984 1.00 0.00
#> sample_18 1 0.000 0.984 1.00 0.00
#> sample_19 1 0.000 0.984 1.00 0.00
#> sample_20 1 0.000 0.984 1.00 0.00
#> sample_21 1 0.000 0.984 1.00 0.00
#> sample_22 2 0.000 0.999 0.00 1.00
#> sample_23 2 0.000 0.999 0.00 1.00
#> sample_24 1 0.000 0.984 1.00 0.00
#> sample_25 2 0.000 0.999 0.00 1.00
#> sample_26 1 0.000 0.984 1.00 0.00
#> sample_27 2 0.000 0.999 0.00 1.00
#> sample_34 2 0.000 0.999 0.00 1.00
#> sample_35 2 0.000 0.999 0.00 1.00
#> sample_36 2 0.000 0.999 0.00 1.00
#> sample_37 2 0.000 0.999 0.00 1.00
#> sample_38 2 0.000 0.999 0.00 1.00
#> sample_28 2 0.000 0.999 0.00 1.00
#> sample_29 1 0.000 0.984 1.00 0.00
#> sample_30 2 0.000 0.999 0.00 1.00
#> sample_31 2 0.000 0.999 0.00 1.00
#> sample_32 2 0.000 0.999 0.00 1.00
#> sample_33 2 0.000 0.999 0.00 1.00
cbind(get_classes(res, k = 3), get_membership(res, k = 3))
#> class entropy silhouette p1 p2 p3
#> sample_39 3 0.2066 0.951 0.00 0.06 0.94
#> sample_40 3 0.0892 0.989 0.00 0.02 0.98
#> sample_42 1 0.0000 0.972 1.00 0.00 0.00
#> sample_47 1 0.0000 0.972 1.00 0.00 0.00
#> sample_48 1 0.0000 0.972 1.00 0.00 0.00
#> sample_49 3 0.0892 0.989 0.00 0.02 0.98
#> sample_41 1 0.0000 0.972 1.00 0.00 0.00
#> sample_43 1 0.0000 0.972 1.00 0.00 0.00
#> sample_44 1 0.0000 0.972 1.00 0.00 0.00
#> sample_45 1 0.0000 0.972 1.00 0.00 0.00
#> sample_46 1 0.0000 0.972 1.00 0.00 0.00
#> sample_70 1 0.0000 0.972 1.00 0.00 0.00
#> sample_71 1 0.2537 0.894 0.92 0.08 0.00
#> sample_72 1 0.0000 0.972 1.00 0.00 0.00
#> sample_68 1 0.0000 0.972 1.00 0.00 0.00
#> sample_69 1 0.0000 0.972 1.00 0.00 0.00
#> sample_67 1 0.0000 0.972 1.00 0.00 0.00
#> sample_55 3 0.0000 0.981 0.00 0.00 1.00
#> sample_56 3 0.0892 0.989 0.00 0.02 0.98
#> sample_59 1 0.2537 0.903 0.92 0.00 0.08
#> sample_52 2 0.0000 1.000 0.00 1.00 0.00
#> sample_53 2 0.0000 1.000 0.00 1.00 0.00
#> sample_51 2 0.0000 1.000 0.00 1.00 0.00
#> sample_50 2 0.0000 1.000 0.00 1.00 0.00
#> sample_54 1 0.0892 0.962 0.98 0.00 0.02
#> sample_57 2 0.0000 1.000 0.00 1.00 0.00
#> sample_58 2 0.0000 1.000 0.00 1.00 0.00
#> sample_60 1 0.8143 0.322 0.56 0.08 0.36
#> sample_61 2 0.0000 1.000 0.00 1.00 0.00
#> sample_65 2 0.0000 1.000 0.00 1.00 0.00
#> sample_66 1 0.0000 0.972 1.00 0.00 0.00
#> sample_63 2 0.0000 1.000 0.00 1.00 0.00
#> sample_64 2 0.0000 1.000 0.00 1.00 0.00
#> sample_62 2 0.0000 1.000 0.00 1.00 0.00
#> sample_1 3 0.0000 0.981 0.00 0.00 1.00
#> sample_2 1 0.0000 0.972 1.00 0.00 0.00
#> sample_3 3 0.0000 0.981 0.00 0.00 1.00
#> sample_4 3 0.0000 0.981 0.00 0.00 1.00
#> sample_5 1 0.0000 0.972 1.00 0.00 0.00
#> sample_6 3 0.0892 0.989 0.00 0.02 0.98
#> sample_7 3 0.0892 0.989 0.00 0.02 0.98
#> sample_8 3 0.0892 0.989 0.00 0.02 0.98
#> sample_9 1 0.0000 0.972 1.00 0.00 0.00
#> sample_10 1 0.0892 0.962 0.98 0.00 0.02
#> sample_11 1 0.0000 0.972 1.00 0.00 0.00
#> sample_12 2 0.0000 1.000 0.00 1.00 0.00
#> sample_13 1 0.0000 0.972 1.00 0.00 0.00
#> sample_14 1 0.0000 0.972 1.00 0.00 0.00
#> sample_15 1 0.0000 0.972 1.00 0.00 0.00
#> sample_16 1 0.0892 0.962 0.98 0.00 0.02
#> sample_17 1 0.0892 0.962 0.98 0.00 0.02
#> sample_18 1 0.4796 0.738 0.78 0.00 0.22
#> sample_19 1 0.0000 0.972 1.00 0.00 0.00
#> sample_20 1 0.0000 0.972 1.00 0.00 0.00
#> sample_21 1 0.0000 0.972 1.00 0.00 0.00
#> sample_22 2 0.0000 1.000 0.00 1.00 0.00
#> sample_23 3 0.0892 0.989 0.00 0.02 0.98
#> sample_24 1 0.0000 0.972 1.00 0.00 0.00
#> sample_25 2 0.0000 1.000 0.00 1.00 0.00
#> sample_26 1 0.2066 0.930 0.94 0.00 0.06
#> sample_27 3 0.0892 0.989 0.00 0.02 0.98
#> sample_34 2 0.0000 1.000 0.00 1.00 0.00
#> sample_35 2 0.0000 1.000 0.00 1.00 0.00
#> sample_36 2 0.0000 1.000 0.00 1.00 0.00
#> sample_37 2 0.0000 1.000 0.00 1.00 0.00
#> sample_38 2 0.0000 1.000 0.00 1.00 0.00
#> sample_28 2 0.0000 1.000 0.00 1.00 0.00
#> sample_29 1 0.0000 0.972 1.00 0.00 0.00
#> sample_30 2 0.0000 1.000 0.00 1.00 0.00
#> sample_31 2 0.0000 1.000 0.00 1.00 0.00
#> sample_32 2 0.0000 1.000 0.00 1.00 0.00
#> sample_33 2 0.0000 1.000 0.00 1.00 0.00
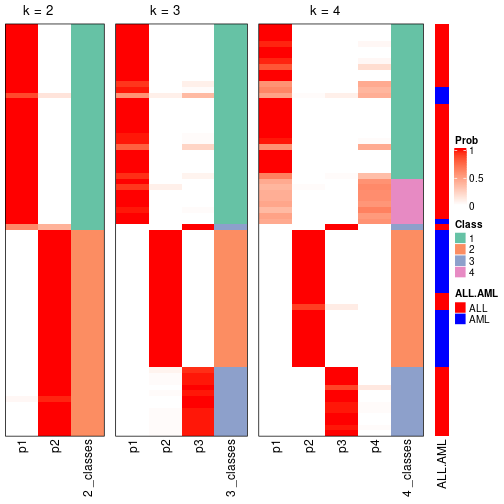
cbind(get_classes(res, k = 4), get_membership(res, k = 4))
#> class entropy silhouette p1 p2 p3 p4
#> sample_39 3 0.0000 0.987 0.00 0.00 1.00 0.00
#> sample_40 3 0.0000 0.987 0.00 0.00 1.00 0.00
#> sample_42 4 0.4948 0.932 0.44 0.00 0.00 0.56
#> sample_47 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_48 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_49 3 0.0000 0.987 0.00 0.00 1.00 0.00
#> sample_41 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_43 1 0.1211 0.812 0.96 0.00 0.00 0.04
#> sample_44 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_45 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_46 1 0.1211 0.807 0.96 0.00 0.00 0.04
#> sample_70 1 0.3400 0.661 0.82 0.00 0.00 0.18
#> sample_71 4 0.5428 0.891 0.38 0.02 0.00 0.60
#> sample_72 4 0.4907 0.931 0.42 0.00 0.00 0.58
#> sample_68 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_69 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_67 4 0.4907 0.931 0.42 0.00 0.00 0.58
#> sample_55 3 0.2647 0.890 0.00 0.00 0.88 0.12
#> sample_56 3 0.0000 0.987 0.00 0.00 1.00 0.00
#> sample_59 1 0.4948 0.371 0.56 0.00 0.00 0.44
#> sample_52 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_53 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_51 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_50 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_54 1 0.4790 0.435 0.62 0.00 0.00 0.38
#> sample_57 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_58 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_60 1 0.7192 0.248 0.48 0.02 0.08 0.42
#> sample_61 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_65 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_66 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_63 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_64 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_62 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_1 3 0.0000 0.987 0.00 0.00 1.00 0.00
#> sample_2 4 0.4977 0.918 0.46 0.00 0.00 0.54
#> sample_3 3 0.0707 0.979 0.00 0.00 0.98 0.02
#> sample_4 3 0.0000 0.987 0.00 0.00 1.00 0.00
#> sample_5 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_6 3 0.0707 0.979 0.00 0.00 0.98 0.02
#> sample_7 3 0.0000 0.987 0.00 0.00 1.00 0.00
#> sample_8 3 0.0000 0.987 0.00 0.00 1.00 0.00
#> sample_9 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_10 4 0.4713 0.816 0.36 0.00 0.00 0.64
#> sample_11 4 0.4994 0.889 0.48 0.00 0.00 0.52
#> sample_12 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_13 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_14 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_15 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_16 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_17 1 0.0707 0.828 0.98 0.00 0.00 0.02
#> sample_18 1 0.4948 0.352 0.56 0.00 0.00 0.44
#> sample_19 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_20 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_21 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_22 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_23 3 0.0707 0.979 0.00 0.00 0.98 0.02
#> sample_24 1 0.0000 0.846 1.00 0.00 0.00 0.00
#> sample_25 2 0.2345 0.889 0.00 0.90 0.10 0.00
#> sample_26 1 0.5271 0.456 0.64 0.00 0.02 0.34
#> sample_27 3 0.0000 0.987 0.00 0.00 1.00 0.00
#> sample_34 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_35 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_36 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_37 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_38 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_28 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_29 4 0.4948 0.932 0.44 0.00 0.00 0.56
#> sample_30 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_31 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_32 2 0.0000 0.996 0.00 1.00 0.00 0.00
#> sample_33 2 0.0000 0.996 0.00 1.00 0.00 0.00
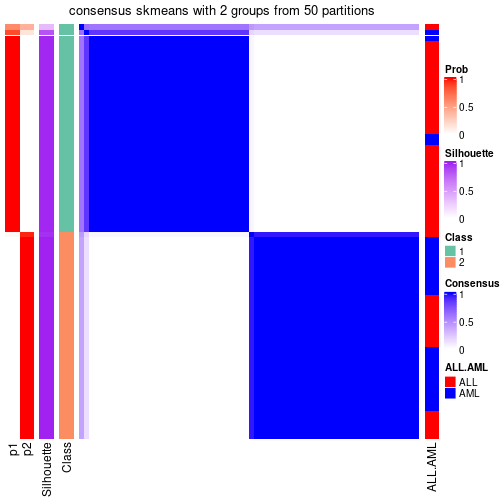
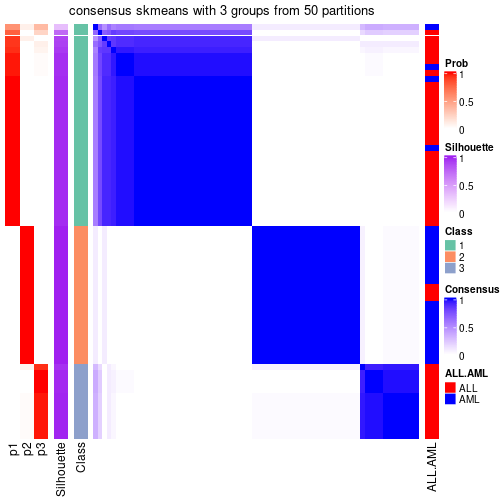
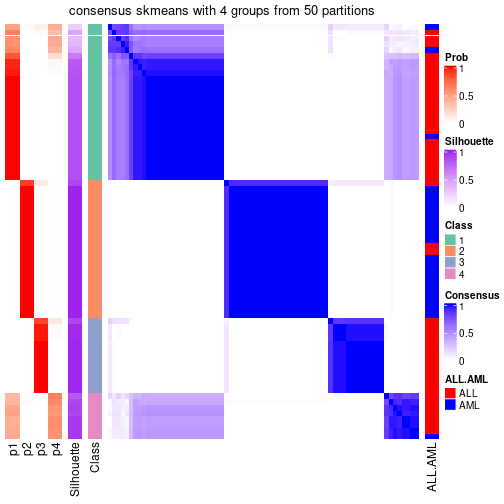
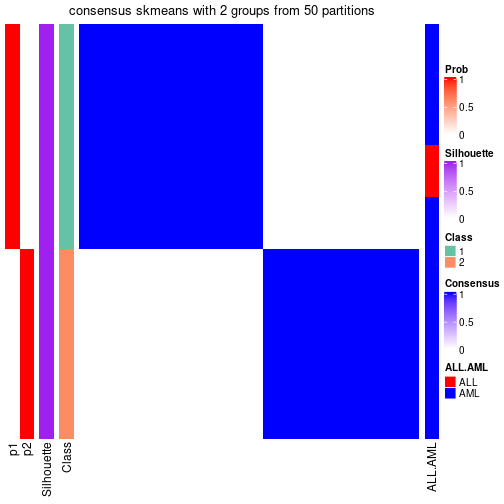
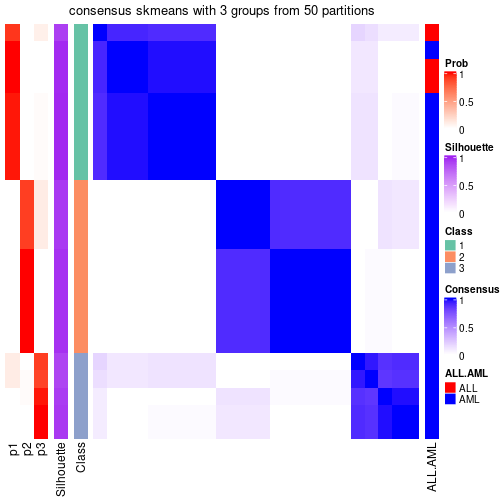
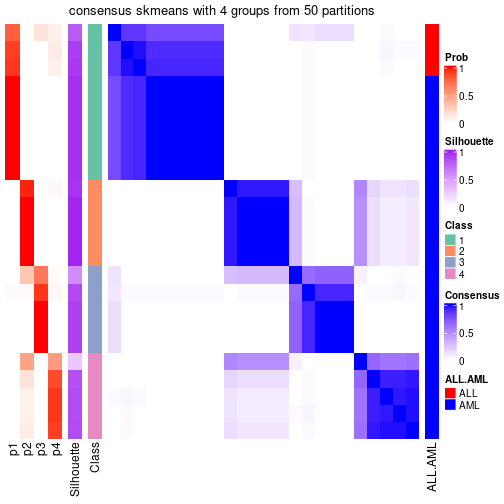
Heatmaps for the consensus matrix. It visualizes the probability of two samples to be in a same group.
consensus_heatmap(res, k = 2)
consensus_heatmap(res, k = 3)
consensus_heatmap(res, k = 4)
Heatmaps for the membership of samples in all partitions to see how consistent they are:
membership_heatmap(res, k = 2)
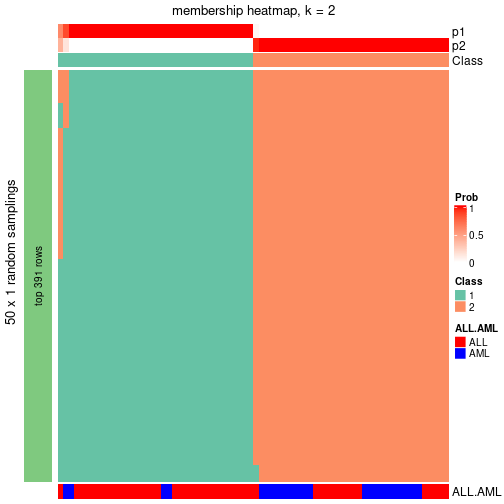
membership_heatmap(res, k = 3)
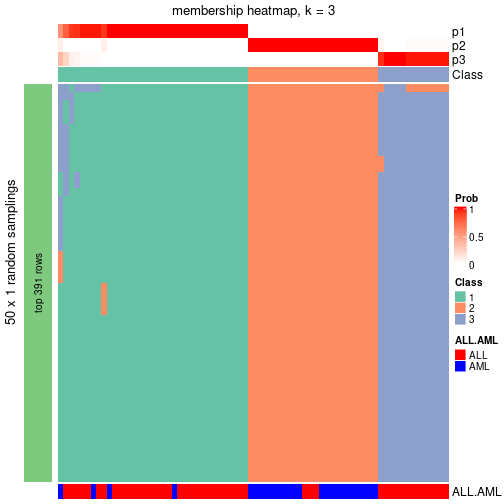
membership_heatmap(res, k = 4)
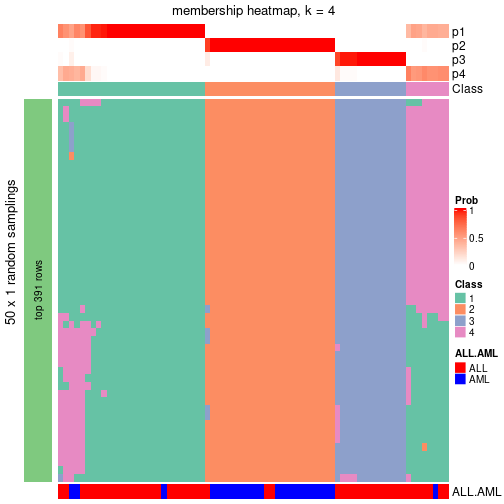
As soon as the classes for columns are determined, the signatures that are significantly different between subgroups can be looked for. Following are the heatmaps for signatures.
Signature heatmaps where rows are scaled:
Signature heatmaps where rows are not scaled:
get_signatures(res, k = 2, scale_rows = FALSE)
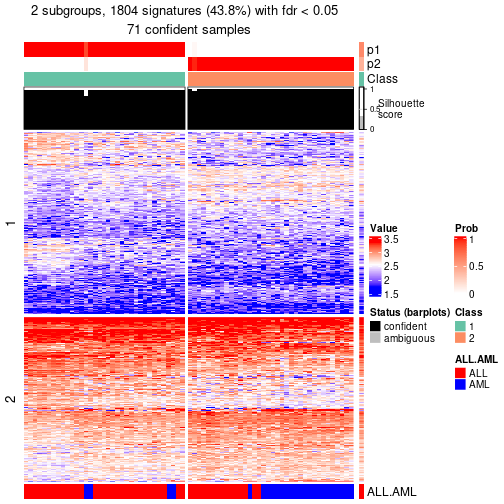
get_signatures(res, k = 3, scale_rows = FALSE)
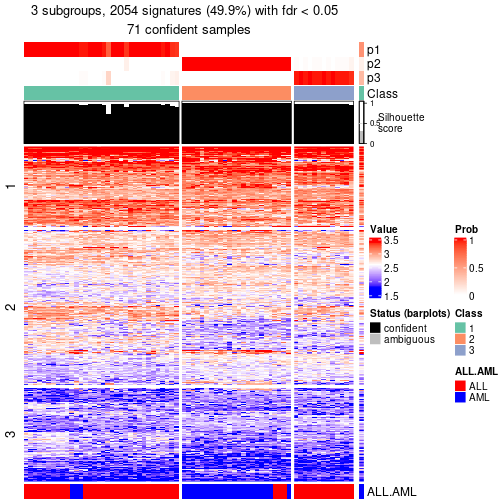
get_signatures(res, k = 4, scale_rows = FALSE)
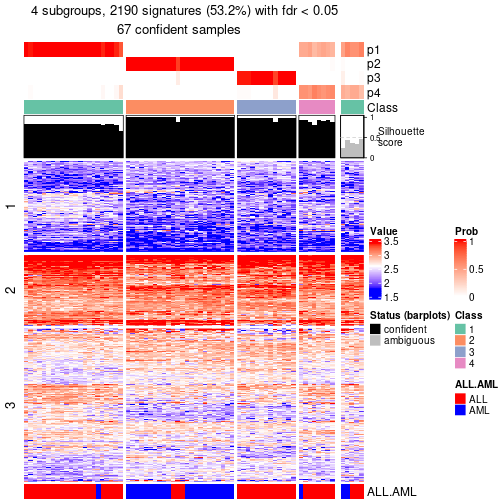
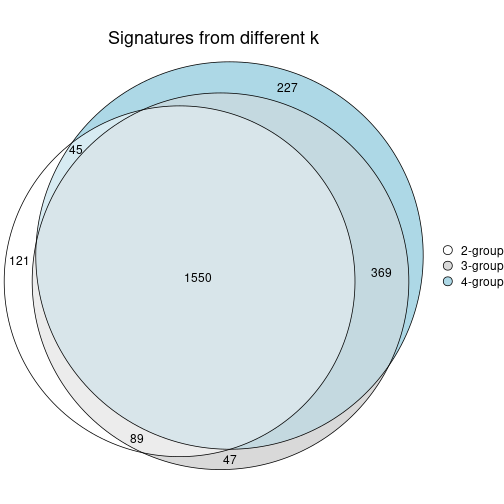
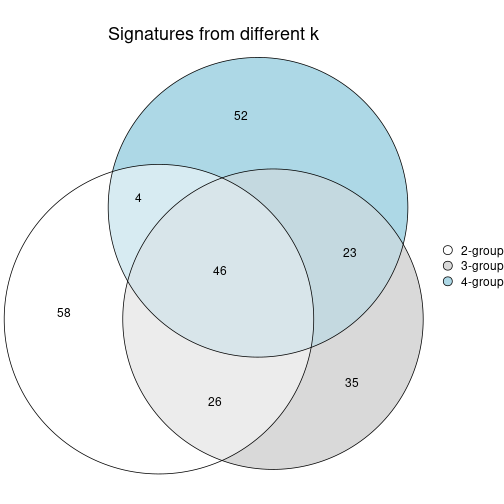
Compare the overlap of signatures from different k:
compare_signatures(res)
get_signature() returns a data frame invisibly. To get the list of signatures, the function
call should be assigned to a variable explicitly. In following code, if plot argument is set
to FALSE, no heatmap is plotted while only the differential analysis is performed.
# code only for demonstration
tb = get_signature(res, k = ..., plot = FALSE)
An example of the output of tb is:
#> which_row fdr mean_1 mean_2 scaled_mean_1 scaled_mean_2 km
#> 1 38 0.042760348 8.373488 9.131774 -0.5533452 0.5164555 1
#> 2 40 0.018707592 7.106213 8.469186 -0.6173731 0.5762149 1
#> 3 55 0.019134737 10.221463 11.207825 -0.6159697 0.5749050 1
#> 4 59 0.006059896 5.921854 7.869574 -0.6899429 0.6439467 1
#> 5 60 0.018055526 8.928898 10.211722 -0.6204761 0.5791110 1
#> 6 98 0.009384629 15.714769 14.887706 0.6635654 -0.6193277 2
...
The columns in tb are:
which_row: row indices corresponding to the input matrix.fdr: FDR for the differential test. mean_x: The mean value in group x.scaled_mean_x: The mean value in group x after rows are scaled.km: Row groups if k-means clustering is applied to rows (which is done by automatically selecting number of clusters).If there are too many signatures, top_signatures = ... can be set to only show the
signatures with the highest FDRs:
# code only for demonstration
# e.g. to show the top 500 most significant rows
tb = get_signature(res, k = ..., top_signatures = 500)
If the signatures are defined as these which are uniquely high in current group, diff_method argument
can be set to "uniquely_high_in_one_group":
# code only for demonstration
tb = get_signature(res, k = ..., diff_method = "uniquely_high_in_one_group")
UMAP plot which shows how samples are separated.
dimension_reduction(res, k = 2, method = "UMAP")
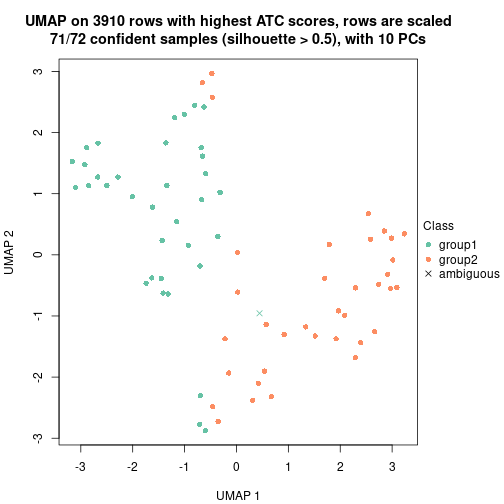
dimension_reduction(res, k = 3, method = "UMAP")
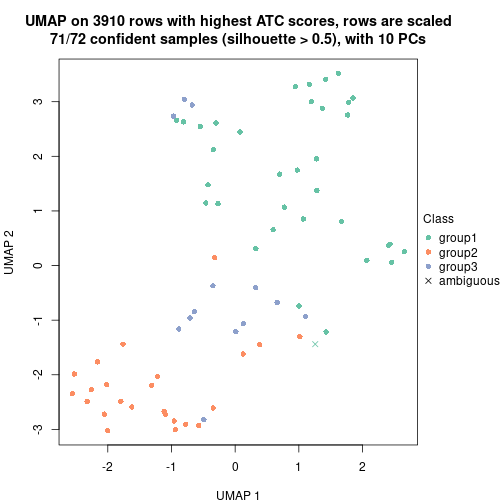
dimension_reduction(res, k = 4, method = "UMAP")
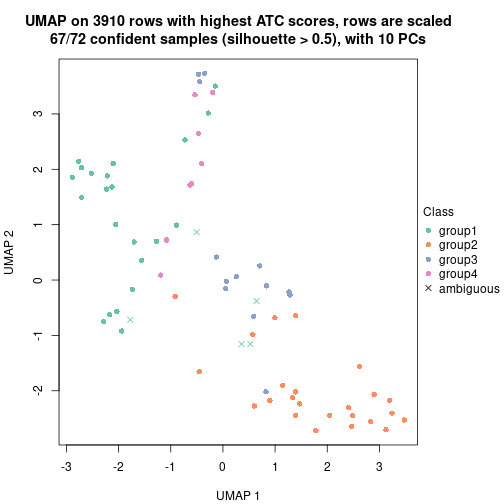
Following heatmap shows how subgroups are split when increasing k:
collect_classes(res)
Test correlation between subgroups and known annotations. If the known annotation is numeric, one-way ANOVA test is applied, and if the known annotation is discrete, chi-squared contingency table test is applied.
test_to_known_factors(res)
#> n_sample ALL.AML(p-value) k
#> ATC:skmeans 71 1.01e-04 2
#> ATC:skmeans 71 6.09e-11 3
#> ATC:skmeans 67 3.09e-10 4
If matrix rows can be associated to genes, consider to use functional_enrichment(res,
...) to perform function enrichment for the signature genes. See this vignette for more detailed explanations.
Parent node: Node0. Child nodes: Node011-leaf , Node012-leaf , Node013-leaf , Node021-leaf , Node022-leaf .
The object with results only for a single top-value method and a single partitioning method can be extracted as:
res = res_rh["01"]
A summary of res and all the functions that can be applied to it:
res
#> A 'ConsensusPartition' object with k = 2, 3, 4.
#> On a matrix with 3910 rows and 35 columns.
#> Top rows (391) are extracted by 'ATC' method.
#> Subgroups are detected by 'skmeans' method.
#> Performed in total 150 partitions by row resampling.
#> Best k for subgroups seems to be 3.
#>
#> Following methods can be applied to this 'ConsensusPartition' object:
#> [1] "cola_report" "collect_classes" "collect_plots"
#> [4] "collect_stats" "colnames" "compare_partitions"
#> [7] "compare_signatures" "consensus_heatmap" "dimension_reduction"
#> [10] "functional_enrichment" "get_anno_col" "get_anno"
#> [13] "get_classes" "get_consensus" "get_matrix"
#> [16] "get_membership" "get_param" "get_signatures"
#> [19] "get_stats" "is_best_k" "is_stable_k"
#> [22] "membership_heatmap" "ncol" "nrow"
#> [25] "plot_ecdf" "predict_classes" "rownames"
#> [28] "select_partition_number" "show" "suggest_best_k"
#> [31] "test_to_known_factors" "top_rows_heatmap"
collect_plots() function collects all the plots made from res for all k (number of subgroups)
into one single page to provide an easy and fast comparison between different k.
collect_plots(res)
The plots are:
k and the heatmap of
predicted classes for each k.k.k.k.All the plots in panels can be made by individual functions and they are plotted later in this section.
select_partition_number() produces several plots showing different
statistics for choosing “optimized” k. There are following statistics:
k;k, the area increased is defined as \(A_k - A_{k-1}\).The detailed explanations of these statistics can be found in the cola vignette.
Generally speaking, higher 1-PAC score, higher mean silhouette score or higher
concordance corresponds to better partition. Rand index and Jaccard index
measure how similar the current partition is compared to partition with k-1.
If they are too similar, we won't accept k is better than k-1.
select_partition_number(res)
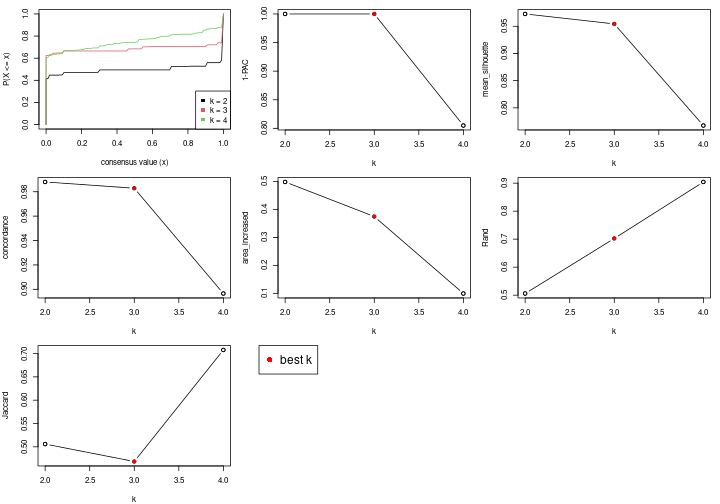
The numeric values for all these statistics can be obtained by get_stats().
get_stats(res)
#> k 1-PAC mean_silhouette concordance area_increased Rand Jaccard
#> 2 2 1.000 0.973 0.988 0.4982 0.506 0.506
#> 3 3 1.000 0.954 0.983 0.3745 0.703 0.468
#> 4 4 0.805 0.767 0.897 0.0993 0.904 0.708
suggest_best_k() suggests the best \(k\) based on these statistics. The rules are as follows:
suggest_best_k(res)
#> [1] 3
#> attr(,"optional")
#> [1] 2
There is also optional best \(k\) = 2 that is worth to check.
Following is the table of the partitions (You need to click the show/hide
code output link to see it). The membership matrix (columns with name p*)
is inferred by
clue::cl_consensus()
function with the SE method. Basically the value in the membership matrix
represents the probability to belong to a certain group. The finall subgroup
label for an item is determined with the group with highest probability it
belongs to.
In get_classes() function, the entropy is calculated from the membership
matrix and the silhouette score is calculated from the consensus matrix.
cbind(get_classes(res, k = 2), get_membership(res, k = 2))
#> class entropy silhouette p1 p2
#> sample_42 2 0.000 0.980 0.00 1.00
#> sample_47 1 0.000 0.998 1.00 0.00
#> sample_48 1 0.000 0.998 1.00 0.00
#> sample_41 1 0.000 0.998 1.00 0.00
#> sample_43 2 0.000 0.980 0.00 1.00
#> sample_44 2 0.469 0.883 0.10 0.90
#> sample_45 2 0.881 0.585 0.30 0.70
#> sample_46 2 0.000 0.980 0.00 1.00
#> sample_70 2 0.000 0.980 0.00 1.00
#> sample_71 2 0.000 0.980 0.00 1.00
#> sample_72 2 0.000 0.980 0.00 1.00
#> sample_68 1 0.000 0.998 1.00 0.00
#> sample_69 1 0.000 0.998 1.00 0.00
#> sample_67 2 0.000 0.980 0.00 1.00
#> sample_59 2 0.000 0.980 0.00 1.00
#> sample_54 2 0.000 0.980 0.00 1.00
#> sample_60 2 0.000 0.980 0.00 1.00
#> sample_66 2 0.000 0.980 0.00 1.00
#> sample_2 2 0.000 0.980 0.00 1.00
#> sample_5 1 0.000 0.998 1.00 0.00
#> sample_9 2 0.000 0.980 0.00 1.00
#> sample_10 2 0.000 0.980 0.00 1.00
#> sample_11 2 0.000 0.980 0.00 1.00
#> sample_13 1 0.000 0.998 1.00 0.00
#> sample_14 1 0.141 0.979 0.98 0.02
#> sample_15 1 0.000 0.998 1.00 0.00
#> sample_16 1 0.000 0.998 1.00 0.00
#> sample_17 1 0.000 0.998 1.00 0.00
#> sample_18 2 0.000 0.980 0.00 1.00
#> sample_19 2 0.000 0.980 0.00 1.00
#> sample_20 1 0.000 0.998 1.00 0.00
#> sample_21 1 0.000 0.998 1.00 0.00
#> sample_24 1 0.000 0.998 1.00 0.00
#> sample_26 2 0.000 0.980 0.00 1.00
#> sample_29 2 0.000 0.980 0.00 1.00
cbind(get_classes(res, k = 3), get_membership(res, k = 3))
#> class entropy silhouette p1 p2 p3
#> sample_42 3 0.000 0.990 0.00 0.00 1.0
#> sample_47 2 0.628 0.159 0.46 0.54 0.0
#> sample_48 1 0.000 1.000 1.00 0.00 0.0
#> sample_41 1 0.000 1.000 1.00 0.00 0.0
#> sample_43 2 0.000 0.958 0.00 1.00 0.0
#> sample_44 2 0.000 0.958 0.00 1.00 0.0
#> sample_45 2 0.000 0.958 0.00 1.00 0.0
#> sample_46 2 0.000 0.958 0.00 1.00 0.0
#> sample_70 2 0.000 0.958 0.00 1.00 0.0
#> sample_71 3 0.000 0.990 0.00 0.00 1.0
#> sample_72 3 0.000 0.990 0.00 0.00 1.0
#> sample_68 1 0.000 1.000 1.00 0.00 0.0
#> sample_69 1 0.000 1.000 1.00 0.00 0.0
#> sample_67 3 0.000 0.990 0.00 0.00 1.0
#> sample_59 2 0.000 0.958 0.00 1.00 0.0
#> sample_54 2 0.000 0.958 0.00 1.00 0.0
#> sample_60 2 0.000 0.958 0.00 1.00 0.0
#> sample_66 3 0.000 0.990 0.00 0.00 1.0
#> sample_2 3 0.000 0.990 0.00 0.00 1.0
#> sample_5 1 0.000 1.000 1.00 0.00 0.0
#> sample_9 3 0.000 0.990 0.00 0.00 1.0
#> sample_10 3 0.000 0.990 0.00 0.00 1.0
#> sample_11 3 0.000 0.990 0.00 0.00 1.0
#> sample_13 1 0.000 1.000 1.00 0.00 0.0
#> sample_14 3 0.296 0.888 0.10 0.00 0.9
#> sample_15 1 0.000 1.000 1.00 0.00 0.0
#> sample_16 2 0.153 0.924 0.04 0.96 0.0
#> sample_17 1 0.000 1.000 1.00 0.00 0.0
#> sample_18 2 0.000 0.958 0.00 1.00 0.0
#> sample_19 2 0.000 0.958 0.00 1.00 0.0
#> sample_20 1 0.000 1.000 1.00 0.00 0.0
#> sample_21 1 0.000 1.000 1.00 0.00 0.0
#> sample_24 1 0.000 1.000 1.00 0.00 0.0
#> sample_26 2 0.000 0.958 0.00 1.00 0.0
#> sample_29 3 0.000 0.990 0.00 0.00 1.0
cbind(get_classes(res, k = 4), get_membership(res, k = 4))
#> class entropy silhouette p1 p2 p3 p4
#> sample_42 3 0.000 0.921 0.00 0.00 1.00 0.00
#> sample_47 4 0.648 0.426 0.30 0.10 0.00 0.60
#> sample_48 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_41 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_43 2 0.000 0.801 0.00 1.00 0.00 0.00
#> sample_44 2 0.000 0.801 0.00 1.00 0.00 0.00
#> sample_45 2 0.000 0.801 0.00 1.00 0.00 0.00
#> sample_46 2 0.000 0.801 0.00 1.00 0.00 0.00
#> sample_70 2 0.000 0.801 0.00 1.00 0.00 0.00
#> sample_71 3 0.000 0.921 0.00 0.00 1.00 0.00
#> sample_72 3 0.000 0.921 0.00 0.00 1.00 0.00
#> sample_68 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_69 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_67 3 0.000 0.921 0.00 0.00 1.00 0.00
#> sample_59 2 0.000 0.801 0.00 1.00 0.00 0.00
#> sample_54 2 0.499 0.226 0.00 0.52 0.00 0.48
#> sample_60 2 0.499 0.226 0.00 0.52 0.00 0.48
#> sample_66 3 0.265 0.893 0.00 0.00 0.88 0.12
#> sample_2 3 0.121 0.916 0.00 0.00 0.96 0.04
#> sample_5 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_9 3 0.441 0.714 0.00 0.00 0.70 0.30
#> sample_10 3 0.317 0.867 0.00 0.00 0.84 0.16
#> sample_11 3 0.265 0.893 0.00 0.00 0.88 0.12
#> sample_13 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_14 4 0.543 -0.119 0.02 0.00 0.38 0.60
#> sample_15 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_16 4 0.380 0.435 0.00 0.22 0.00 0.78
#> sample_17 4 0.234 0.542 0.10 0.00 0.00 0.90
#> sample_18 2 0.471 0.461 0.00 0.64 0.00 0.36
#> sample_19 4 0.462 0.225 0.00 0.34 0.00 0.66
#> sample_20 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_21 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_24 1 0.000 1.000 1.00 0.00 0.00 0.00
#> sample_26 2 0.234 0.745 0.00 0.90 0.00 0.10
#> sample_29 3 0.000 0.921 0.00 0.00 1.00 0.00
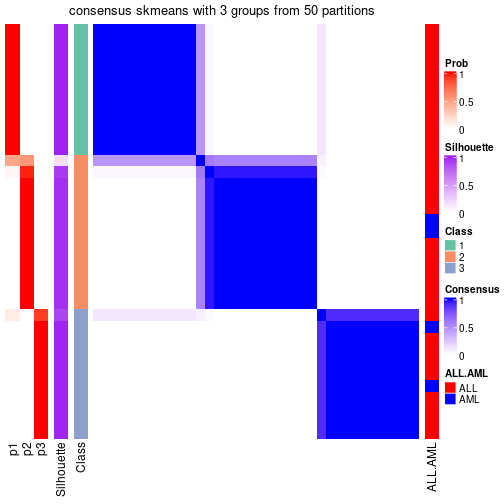
Heatmaps for the consensus matrix. It visualizes the probability of two samples to be in a same group.
consensus_heatmap(res, k = 2)
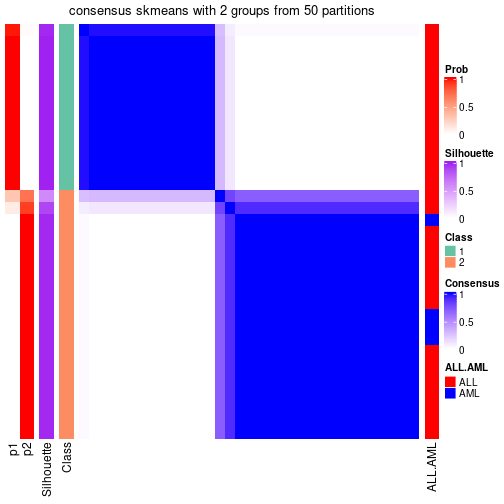
consensus_heatmap(res, k = 3)
consensus_heatmap(res, k = 4)
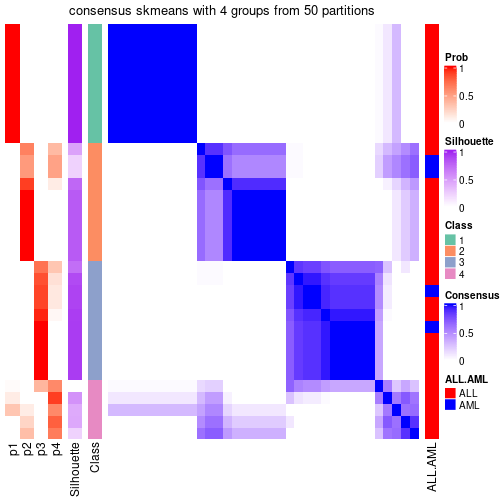
Heatmaps for the membership of samples in all partitions to see how consistent they are:
membership_heatmap(res, k = 2)
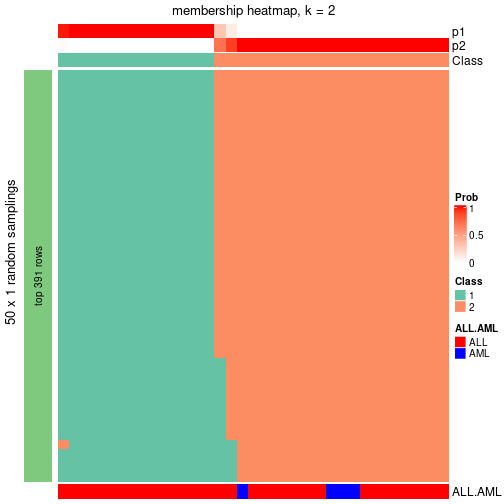
membership_heatmap(res, k = 3)
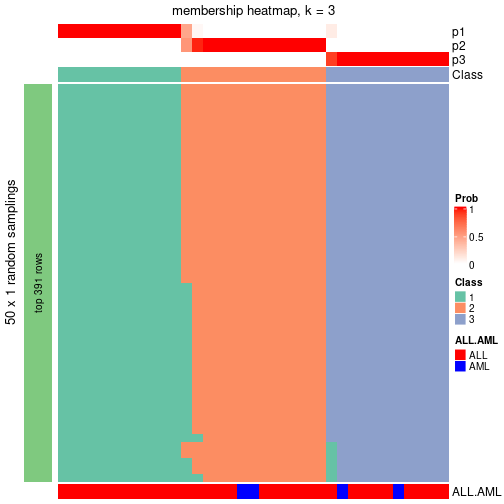
membership_heatmap(res, k = 4)
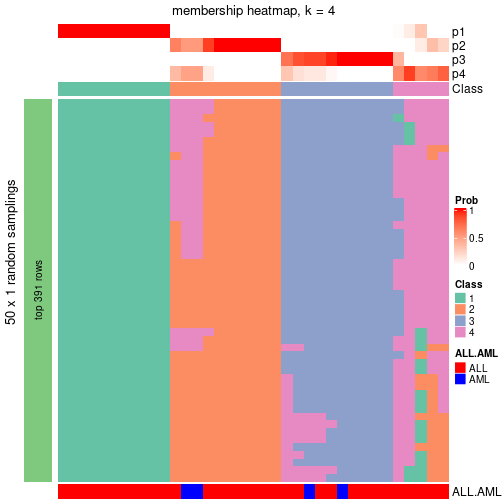
As soon as the classes for columns are determined, the signatures that are significantly different between subgroups can be looked for. Following are the heatmaps for signatures.
Signature heatmaps where rows are scaled:
Signature heatmaps where rows are not scaled:
get_signatures(res, k = 2, scale_rows = FALSE)
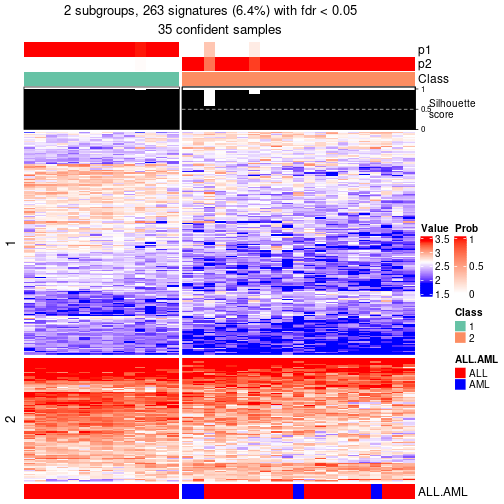
get_signatures(res, k = 3, scale_rows = FALSE)
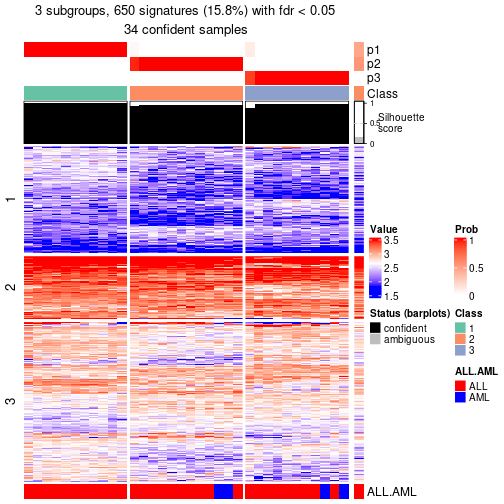
get_signatures(res, k = 4, scale_rows = FALSE)
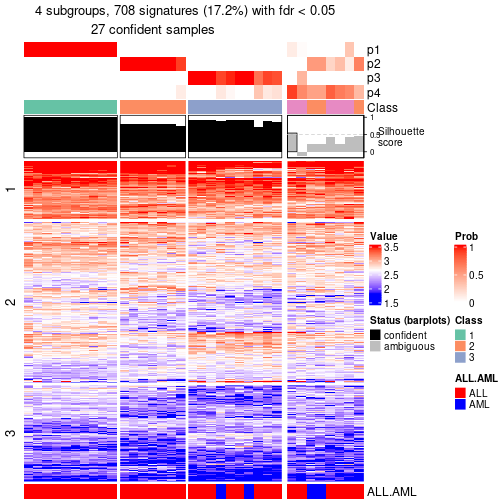
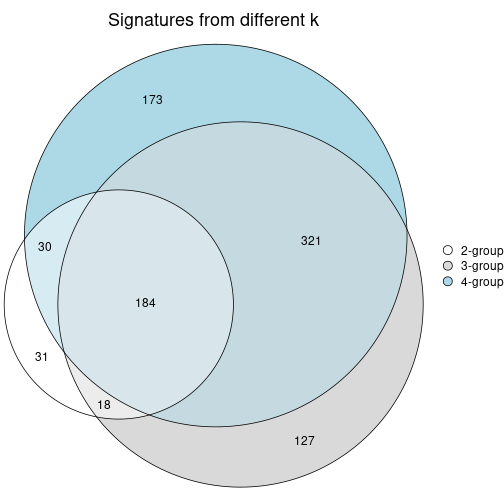
Compare the overlap of signatures from different k:
compare_signatures(res)
get_signature() returns a data frame invisibly. To get the list of signatures, the function
call should be assigned to a variable explicitly. In following code, if plot argument is set
to FALSE, no heatmap is plotted while only the differential analysis is performed.
# code only for demonstration
tb = get_signature(res, k = ..., plot = FALSE)
An example of the output of tb is:
#> which_row fdr mean_1 mean_2 scaled_mean_1 scaled_mean_2 km
#> 1 38 0.042760348 8.373488 9.131774 -0.5533452 0.5164555 1
#> 2 40 0.018707592 7.106213 8.469186 -0.6173731 0.5762149 1
#> 3 55 0.019134737 10.221463 11.207825 -0.6159697 0.5749050 1
#> 4 59 0.006059896 5.921854 7.869574 -0.6899429 0.6439467 1
#> 5 60 0.018055526 8.928898 10.211722 -0.6204761 0.5791110 1
#> 6 98 0.009384629 15.714769 14.887706 0.6635654 -0.6193277 2
...
The columns in tb are:
which_row: row indices corresponding to the input matrix.fdr: FDR for the differential test. mean_x: The mean value in group x.scaled_mean_x: The mean value in group x after rows are scaled.km: Row groups if k-means clustering is applied to rows (which is done by automatically selecting number of clusters).If there are too many signatures, top_signatures = ... can be set to only show the
signatures with the highest FDRs:
# code only for demonstration
# e.g. to show the top 500 most significant rows
tb = get_signature(res, k = ..., top_signatures = 500)
If the signatures are defined as these which are uniquely high in current group, diff_method argument
can be set to "uniquely_high_in_one_group":
# code only for demonstration
tb = get_signature(res, k = ..., diff_method = "uniquely_high_in_one_group")
UMAP plot which shows how samples are separated.
dimension_reduction(res, k = 2, method = "UMAP")
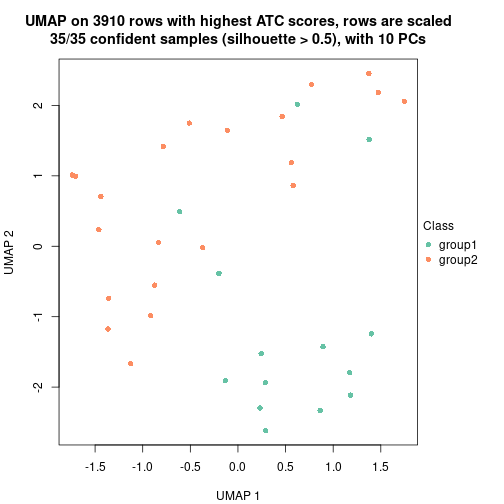
dimension_reduction(res, k = 3, method = "UMAP")
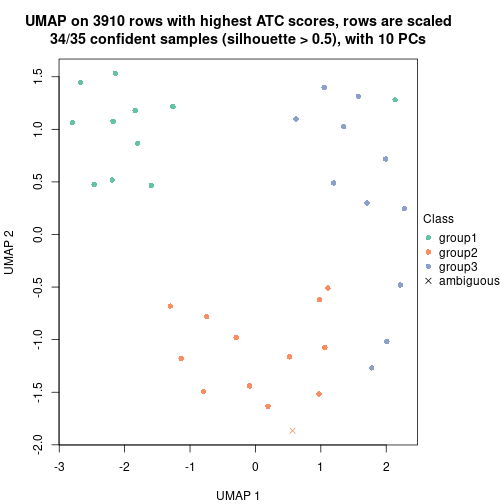
dimension_reduction(res, k = 4, method = "UMAP")
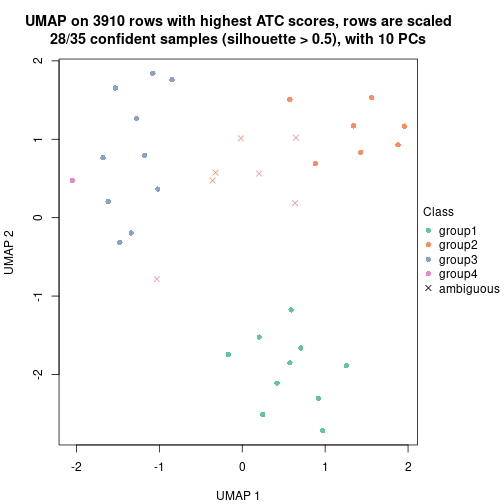
Following heatmap shows how subgroups are split when increasing k:
collect_classes(res)
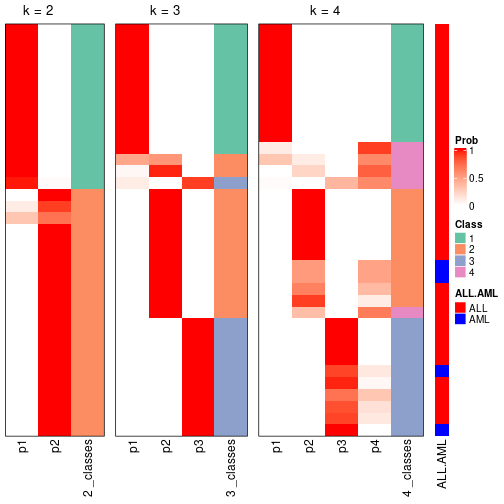
Test correlation between subgroups and known annotations. If the known annotation is numeric, one-way ANOVA test is applied, and if the known annotation is discrete, chi-squared contingency table test is applied.
test_to_known_factors(res)
#> n_sample ALL.AML(p-value) k
#> ATC:skmeans 35 0.233 2
#> ATC:skmeans 34 0.336 3
#> ATC:skmeans 28 0.275 4
If matrix rows can be associated to genes, consider to use functional_enrichment(res,
...) to perform function enrichment for the signature genes. See this vignette for more detailed explanations.
Parent node: Node0. Child nodes: Node011-leaf , Node012-leaf , Node013-leaf , Node021-leaf , Node022-leaf .
The object with results only for a single top-value method and a single partitioning method can be extracted as:
res = res_rh["02"]
A summary of res and all the functions that can be applied to it:
res
#> A 'ConsensusPartition' object with k = 2, 3, 4.
#> On a matrix with 3910 rows and 24 columns.
#> Top rows (391) are extracted by 'ATC' method.
#> Subgroups are detected by 'skmeans' method.
#> Performed in total 150 partitions by row resampling.
#> Best k for subgroups seems to be 2.
#>
#> Following methods can be applied to this 'ConsensusPartition' object:
#> [1] "cola_report" "collect_classes" "collect_plots"
#> [4] "collect_stats" "colnames" "compare_partitions"
#> [7] "compare_signatures" "consensus_heatmap" "dimension_reduction"
#> [10] "functional_enrichment" "get_anno_col" "get_anno"
#> [13] "get_classes" "get_consensus" "get_matrix"
#> [16] "get_membership" "get_param" "get_signatures"
#> [19] "get_stats" "is_best_k" "is_stable_k"
#> [22] "membership_heatmap" "ncol" "nrow"
#> [25] "plot_ecdf" "predict_classes" "rownames"
#> [28] "select_partition_number" "show" "suggest_best_k"
#> [31] "test_to_known_factors" "top_rows_heatmap"
collect_plots() function collects all the plots made from res for all k (number of subgroups)
into one single page to provide an easy and fast comparison between different k.
collect_plots(res)
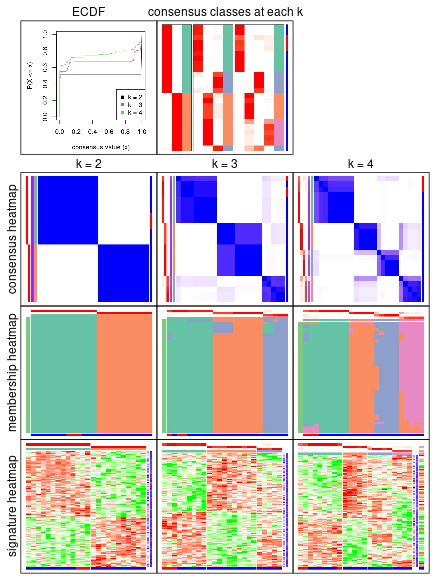
The plots are:
k and the heatmap of
predicted classes for each k.k.k.k.All the plots in panels can be made by individual functions and they are plotted later in this section.
select_partition_number() produces several plots showing different
statistics for choosing “optimized” k. There are following statistics:
k;k, the area increased is defined as \(A_k - A_{k-1}\).The detailed explanations of these statistics can be found in the cola vignette.
Generally speaking, higher 1-PAC score, higher mean silhouette score or higher
concordance corresponds to better partition. Rand index and Jaccard index
measure how similar the current partition is compared to partition with k-1.
If they are too similar, we won't accept k is better than k-1.
select_partition_number(res)
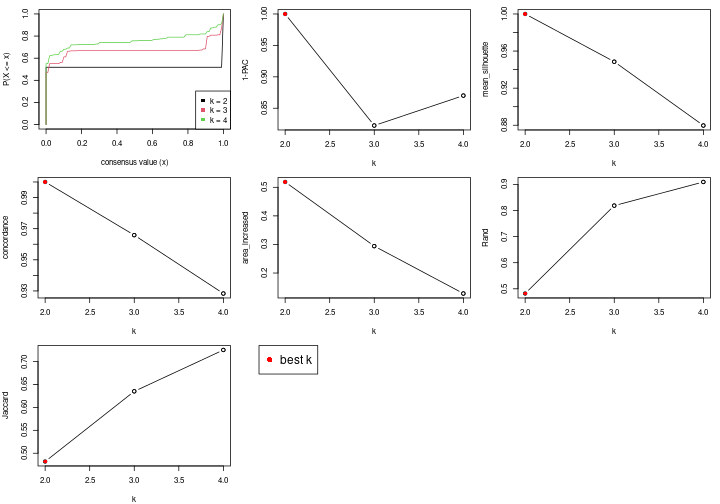
The numeric values for all these statistics can be obtained by get_stats().
get_stats(res)
#> k 1-PAC mean_silhouette concordance area_increased Rand Jaccard
#> 2 2 1.000 1.000 1.000 0.519 0.482 0.482
#> 3 3 0.823 0.949 0.966 0.294 0.819 0.635
#> 4 4 0.870 0.880 0.928 0.128 0.909 0.725
suggest_best_k() suggests the best \(k\) based on these statistics. The rules are as follows:
suggest_best_k(res)
#> [1] 2
Following is the table of the partitions (You need to click the show/hide
code output link to see it). The membership matrix (columns with name p*)
is inferred by
clue::cl_consensus()
function with the SE method. Basically the value in the membership matrix
represents the probability to belong to a certain group. The finall subgroup
label for an item is determined with the group with highest probability it
belongs to.
In get_classes() function, the entropy is calculated from the membership
matrix and the silhouette score is calculated from the consensus matrix.
cbind(get_classes(res, k = 2), get_membership(res, k = 2))
#> class entropy silhouette p1 p2
#> sample_52 2 0 1 0 1
#> sample_53 1 0 1 1 0
#> sample_51 1 0 1 1 0
#> sample_50 1 0 1 1 0
#> sample_57 2 0 1 0 1
#> sample_58 2 0 1 0 1
#> sample_61 2 0 1 0 1
#> sample_65 2 0 1 0 1
#> sample_63 2 0 1 0 1
#> sample_64 2 0 1 0 1
#> sample_62 2 0 1 0 1
#> sample_12 1 0 1 1 0
#> sample_22 1 0 1 1 0
#> sample_25 1 0 1 1 0
#> sample_34 2 0 1 0 1
#> sample_35 2 0 1 0 1
#> sample_36 1 0 1 1 0
#> sample_37 1 0 1 1 0
#> sample_38 1 0 1 1 0
#> sample_28 1 0 1 1 0
#> sample_30 1 0 1 1 0
#> sample_31 2 0 1 0 1
#> sample_32 1 0 1 1 0
#> sample_33 1 0 1 1 0
cbind(get_classes(res, k = 3), get_membership(res, k = 3))
#> class entropy silhouette p1 p2 p3
#> sample_52 2 0.2959 0.931 0.00 0.90 0.10
#> sample_53 1 0.0892 0.981 0.98 0.00 0.02
#> sample_51 1 0.0892 0.981 0.98 0.00 0.02
#> sample_50 3 0.2959 0.891 0.10 0.00 0.90
#> sample_57 2 0.0000 0.956 0.00 1.00 0.00
#> sample_58 2 0.0000 0.956 0.00 1.00 0.00
#> sample_61 2 0.0000 0.956 0.00 1.00 0.00
#> sample_65 2 0.2959 0.931 0.00 0.90 0.10
#> sample_63 2 0.2959 0.931 0.00 0.90 0.10
#> sample_64 2 0.0000 0.956 0.00 1.00 0.00
#> sample_62 2 0.2959 0.931 0.00 0.90 0.10
#> sample_12 1 0.2537 0.907 0.92 0.00 0.08
#> sample_22 1 0.0000 0.976 1.00 0.00 0.00
#> sample_25 1 0.0000 0.976 1.00 0.00 0.00
#> sample_34 2 0.0000 0.956 0.00 1.00 0.00
#> sample_35 2 0.0000 0.956 0.00 1.00 0.00
#> sample_36 3 0.0000 0.933 0.00 0.00 1.00
#> sample_37 1 0.0892 0.981 0.98 0.00 0.02
#> sample_38 1 0.0000 0.976 1.00 0.00 0.00
#> sample_28 1 0.0892 0.981 0.98 0.00 0.02
#> sample_30 3 0.0000 0.933 0.00 0.00 1.00
#> sample_31 3 0.0892 0.919 0.00 0.02 0.98
#> sample_32 3 0.3832 0.888 0.10 0.02 0.88
#> sample_33 1 0.0892 0.981 0.98 0.00 0.02
cbind(get_classes(res, k = 4), get_membership(res, k = 4))
#> class entropy silhouette p1 p2 p3 p4
#> sample_52 2 0.000 0.987 0.00 1.00 0.00 0.00
#> sample_53 1 0.000 0.957 1.00 0.00 0.00 0.00
#> sample_51 1 0.000 0.957 1.00 0.00 0.00 0.00
#> sample_50 3 0.000 0.900 0.00 0.00 1.00 0.00
#> sample_57 2 0.121 0.945 0.00 0.96 0.00 0.04
#> sample_58 4 0.499 0.277 0.00 0.48 0.00 0.52
#> sample_61 4 0.201 0.856 0.00 0.08 0.00 0.92
#> sample_65 2 0.000 0.987 0.00 1.00 0.00 0.00
#> sample_63 2 0.000 0.987 0.00 1.00 0.00 0.00
#> sample_64 4 0.292 0.848 0.00 0.14 0.00 0.86
#> sample_62 2 0.000 0.987 0.00 1.00 0.00 0.00
#> sample_12 1 0.484 0.795 0.78 0.00 0.14 0.08
#> sample_22 1 0.201 0.926 0.92 0.00 0.00 0.08
#> sample_25 1 0.234 0.916 0.90 0.00 0.00 0.10
#> sample_34 4 0.201 0.857 0.00 0.08 0.00 0.92
#> sample_35 4 0.234 0.863 0.00 0.10 0.00 0.90
#> sample_36 3 0.000 0.900 0.00 0.00 1.00 0.00
#> sample_37 1 0.000 0.957 1.00 0.00 0.00 0.00
#> sample_38 1 0.000 0.957 1.00 0.00 0.00 0.00
#> sample_28 1 0.000 0.957 1.00 0.00 0.00 0.00
#> sample_30 3 0.000 0.900 0.00 0.00 1.00 0.00
#> sample_31 3 0.506 0.570 0.00 0.30 0.68 0.02
#> sample_32 3 0.261 0.867 0.02 0.02 0.92 0.04
#> sample_33 1 0.000 0.957 1.00 0.00 0.00 0.00
Heatmaps for the consensus matrix. It visualizes the probability of two samples to be in a same group.
consensus_heatmap(res, k = 2)
consensus_heatmap(res, k = 3)
consensus_heatmap(res, k = 4)
Heatmaps for the membership of samples in all partitions to see how consistent they are:
membership_heatmap(res, k = 2)
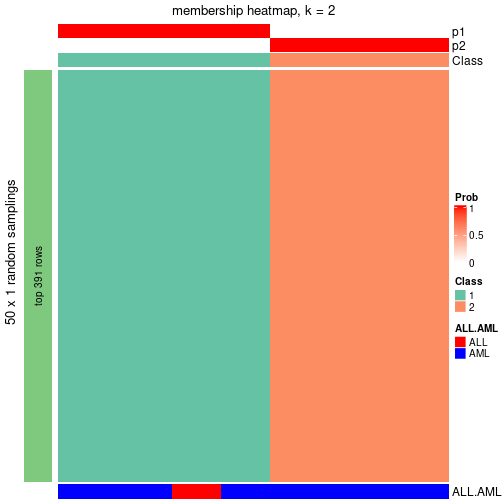
membership_heatmap(res, k = 3)
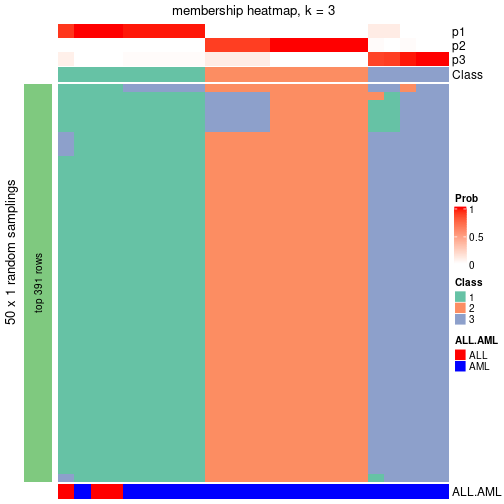
membership_heatmap(res, k = 4)
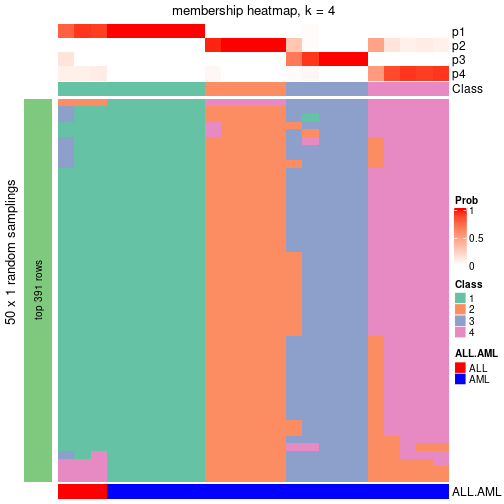
As soon as the classes for columns are determined, the signatures that are significantly different between subgroups can be looked for. Following are the heatmaps for signatures.
Signature heatmaps where rows are scaled:
Signature heatmaps where rows are not scaled:
get_signatures(res, k = 2, scale_rows = FALSE)
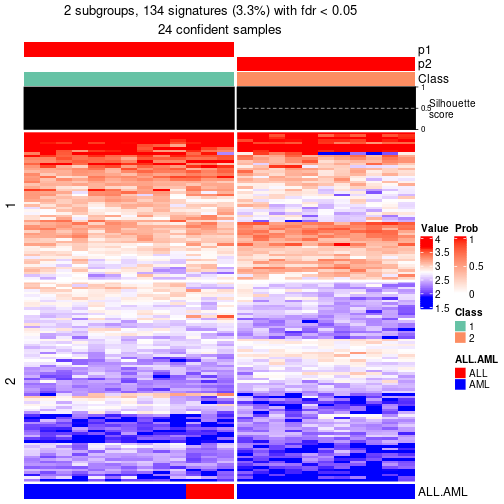
get_signatures(res, k = 3, scale_rows = FALSE)
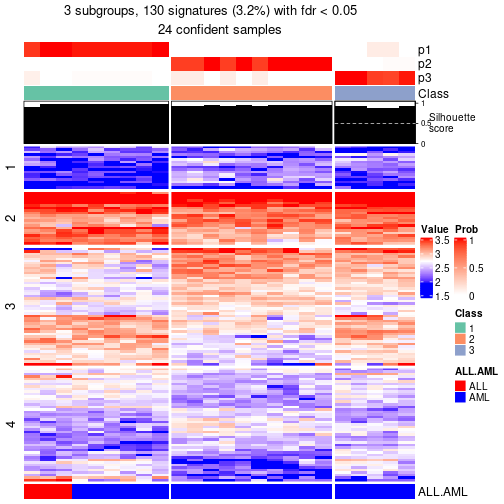
get_signatures(res, k = 4, scale_rows = FALSE)
Compare the overlap of signatures from different k:
compare_signatures(res)
get_signature() returns a data frame invisibly. To get the list of signatures, the function
call should be assigned to a variable explicitly. In following code, if plot argument is set
to FALSE, no heatmap is plotted while only the differential analysis is performed.
# code only for demonstration
tb = get_signature(res, k = ..., plot = FALSE)
An example of the output of tb is:
#> which_row fdr mean_1 mean_2 scaled_mean_1 scaled_mean_2 km
#> 1 38 0.042760348 8.373488 9.131774 -0.5533452 0.5164555 1
#> 2 40 0.018707592 7.106213 8.469186 -0.6173731 0.5762149 1
#> 3 55 0.019134737 10.221463 11.207825 -0.6159697 0.5749050 1
#> 4 59 0.006059896 5.921854 7.869574 -0.6899429 0.6439467 1
#> 5 60 0.018055526 8.928898 10.211722 -0.6204761 0.5791110 1
#> 6 98 0.009384629 15.714769 14.887706 0.6635654 -0.6193277 2
...
The columns in tb are:
which_row: row indices corresponding to the input matrix.fdr: FDR for the differential test. mean_x: The mean value in group x.scaled_mean_x: The mean value in group x after rows are scaled.km: Row groups if k-means clustering is applied to rows (which is done by automatically selecting number of clusters).If there are too many signatures, top_signatures = ... can be set to only show the
signatures with the highest FDRs:
# code only for demonstration
# e.g. to show the top 500 most significant rows
tb = get_signature(res, k = ..., top_signatures = 500)
If the signatures are defined as these which are uniquely high in current group, diff_method argument
can be set to "uniquely_high_in_one_group":
# code only for demonstration
tb = get_signature(res, k = ..., diff_method = "uniquely_high_in_one_group")
UMAP plot which shows how samples are separated.
dimension_reduction(res, k = 2, method = "UMAP")
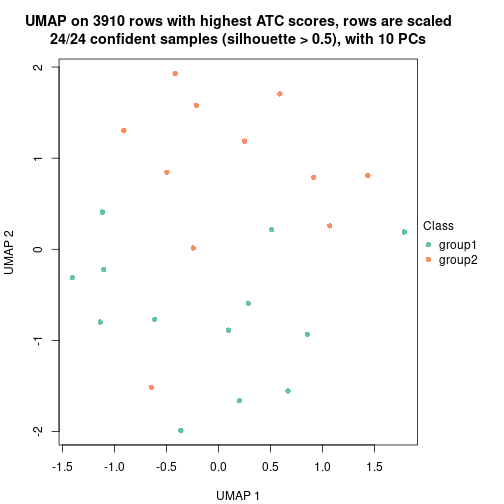
dimension_reduction(res, k = 3, method = "UMAP")
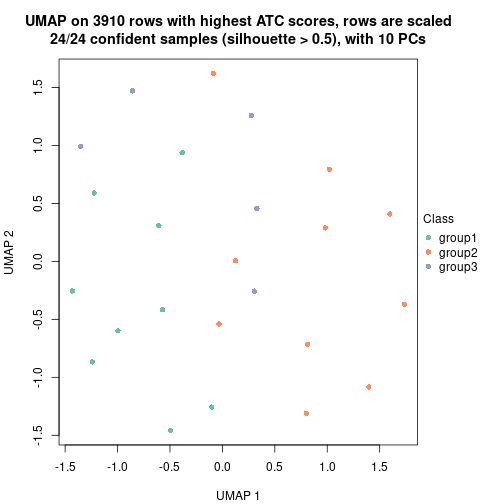
dimension_reduction(res, k = 4, method = "UMAP")
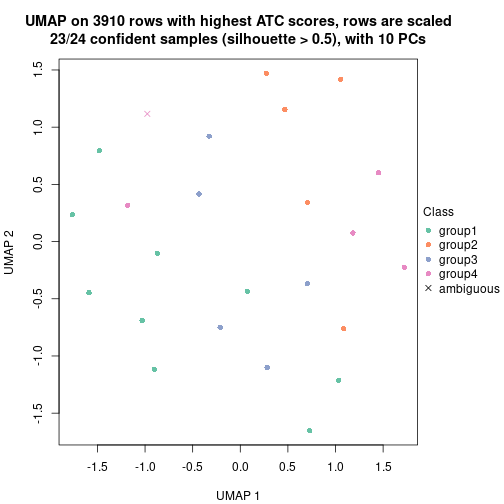
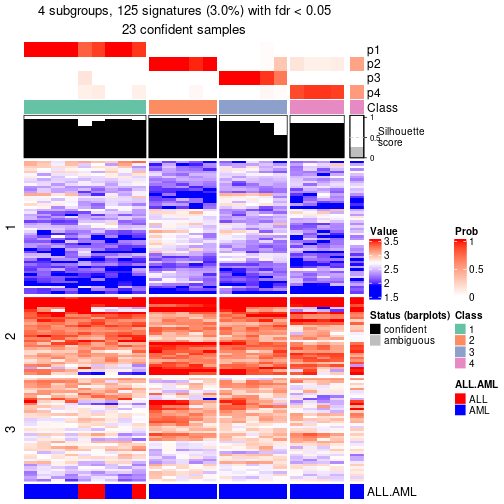
Following heatmap shows how subgroups are split when increasing k:
collect_classes(res)
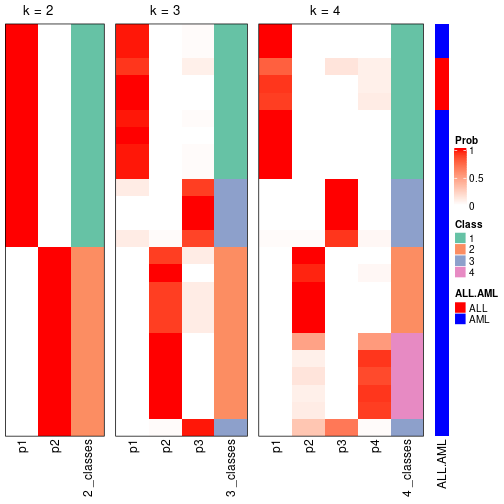
Test correlation between subgroups and known annotations. If the known annotation is numeric, one-way ANOVA test is applied, and if the known annotation is discrete, chi-squared contingency table test is applied.
test_to_known_factors(res)
#> n_sample ALL.AML(p-value) k
#> ATC:skmeans 24 0.2784 2
#> ATC:skmeans 24 0.0574 3
#> ATC:skmeans 23 0.1468 4
If matrix rows can be associated to genes, consider to use functional_enrichment(res,
...) to perform function enrichment for the signature genes. See this vignette for more detailed explanations.
sessionInfo()
#> R version 4.1.0 (2021-05-18)
#> Platform: x86_64-pc-linux-gnu (64-bit)
#> Running under: CentOS Linux 7 (Core)
#>
#> Matrix products: default
#> BLAS/LAPACK: /usr/lib64/libopenblas-r0.3.3.so
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C LC_TIME=en_US.UTF-8
#> [4] LC_COLLATE=en_US.UTF-8 LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C LC_ADDRESS=C
#> [10] LC_TELEPHONE=C LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> attached base packages:
#> [1] grid parallel stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] genefilter_1.74.0 ComplexHeatmap_2.8.0 markdown_1.1 knitr_1.33
#> [5] preprocessCore_1.54.0 golubEsets_1.34.0 Biobase_2.52.0 BiocGenerics_0.38.0
#> [9] cola_1.9.4
#>
#> loaded via a namespace (and not attached):
#> [1] colorspace_2.0-2 rjson_0.2.20 ellipsis_0.3.2 mclust_5.4.7
#> [5] circlize_0.4.13 XVector_0.32.0 GlobalOptions_0.1.2 clue_0.3-59
#> [9] rstudioapi_0.13 bit64_4.0.5 AnnotationDbi_1.54.1 Polychrome_1.3.1
#> [13] RSpectra_0.16-0 fansi_0.5.0 xml2_1.3.2 codetools_0.2-18
#> [17] splines_4.1.0 doParallel_1.0.16 cachem_1.0.5 impute_1.66.0
#> [21] polyclip_1.10-0 jsonlite_1.7.2 Cairo_1.5-12.2 umap_0.2.7.0
#> [25] annotate_1.70.0 cluster_2.1.2 png_0.1-7 data.tree_1.0.0
#> [29] compiler_4.1.0 httr_1.4.2 assertthat_0.2.1 Matrix_1.3-4
#> [33] fastmap_1.1.0 tools_4.1.0 gtable_0.3.0 glue_1.4.2
#> [37] GenomeInfoDbData_1.2.6 dplyr_1.0.7 Rcpp_1.0.7 slam_0.1-48
#> [41] eulerr_6.1.0 vctrs_0.3.8 Biostrings_2.60.1 iterators_1.0.13
#> [45] polylabelr_0.2.0 xfun_0.24 stringr_1.4.0 lifecycle_1.0.0
#> [49] irlba_2.3.3 XML_3.99-0.6 dendextend_1.15.1 zlibbioc_1.38.0
#> [53] scales_1.1.1 microbenchmark_1.4-7 RColorBrewer_1.1-2 memoise_2.0.0
#> [57] reticulate_1.20 gridExtra_2.3 ggplot2_3.3.5 stringi_1.7.3
#> [61] RSQLite_2.2.7 highr_0.9 S4Vectors_0.30.0 foreach_1.5.1
#> [65] shape_1.4.6 GenomeInfoDb_1.28.1 rlang_0.4.11 pkgconfig_2.0.3
#> [69] matrixStats_0.59.0 bitops_1.0-7 evaluate_0.14 lattice_0.20-44
#> [73] purrr_0.3.4 bit_4.0.4 tidyselect_1.1.1 magrittr_2.0.1
#> [77] R6_2.5.0 IRanges_2.26.0 generics_0.1.0 DBI_1.1.1
#> [81] pillar_1.6.1 survival_3.2-11 KEGGREST_1.32.0 scatterplot3d_0.3-41
#> [85] RCurl_1.98-1.3 tibble_3.1.2 crayon_1.4.1 utf8_1.2.1
#> [89] skmeans_0.2-13 viridis_0.6.1 GetoptLong_1.0.5 blob_1.2.1
#> [93] digest_0.6.27 xtable_1.8-4 brew_1.0-6 openssl_1.4.4
#> [97] stats4_4.1.0 munsell_0.5.0 viridisLite_0.4.0 askpass_1.1